NeuroAI for AI Safety
As AI systems become increasingly powerful, the need for safe AI has become more pressing. Humans are an attractive model for AI safety: as the only known agents capable of general intelligence, they perform robustly even under conditions that deviate significantly from prior experiences, explore the world safely, understand pragmatics, and can cooperate to meet their intrinsic goals. Intelligence, when coupled with cooperation and safety mechanisms, can drive sustained progress and well-being. These properties are a function of the architecture of the brain and the learning algorithms it implements. Neuroscience may thus hold important keys to technical AI safety that are currently underexplored and underutilized. In this roadmap, we highlight and critically evaluate several paths toward AI safety inspired by neuroscience: emulating the brain’s representations, information processing, and architecture; building robust sensory and motor systems from imitating brain data and bodies; fine-tuning AI systems on brain data; advancing interpretability using neuroscience methods; and scaling up cognitively-inspired architectures. We make several concrete recommendations for how neuroscience can positively impact AI safety.
Infer the brain’s loss functions
Core idea
AI architectures are trained to optimize loss functions using a learning rule under a specific data distribution. Richards et al. (2019) [140] suggested that brain algorithms can be fruitfully thought of in terms of architectures, loss functions, and learning rules (for an earlier view, see [458]). While architectures and learning can strongly depend on the computational substrate, loss functions are an attractive, implementation-free way of specifying the goals of artificial neural networks.
We evaluate three ways of inferring loss functions of biological systems, at different levels of granularity: first, using the techniques of task-driven neural nets, we could reverse-engineer objective functions leading to the representations in the brain, then transfer them to AI systems. Second, we could infer the reward functions that the brain implements by leveraging the well-characterized link between the brain’s reward systems and reinforcement learning. Finally, we could catalog and estimate evolutionarily ancient loss functions, either imbuing agents with these loss functions or simulating agents which implement these loss functions. We evaluate each of these ideas in turn.
Why does it matter for AI safety and why is neuroscience relevant?
In the framework of [140],
Systems neuroscience seeks explanations for how the brain implements a wide variety of perceptual, cognitive and motor tasks. Conversely, artificial intelligence attempts to design computational systems based on the tasks they will have to solve. In artificial neural networks, the three components specified by design are the objective functions, the learning rules and the architectures. With the growing success of deep learning, which utilizes brain-inspired architectures, these three designed components have increasingly become central to how we model, engineer and optimize complex artificial learning systems. Here we argue that a greater focus on these components would also benefit systems neuroscience.
The relevant abstractions are thus:
The loss functions (or objective functions) implemented by the system
The architecture of the system
The learning rules implemented by the system
To this list, one might add the environment or the stimuli used to train the system, as well as the specific task that the system must solve. Loss functions can be transplanted directly and naturally to artificial systems. It’s been argued that this higher-level form of transfer can be less brittle and lead to better generalization than copying behavior [459].
A different line of research focuses on the reward functions that the brain implements. If we could infer what those human reward functions are and what our motivations are, we could potentially screen them and implement relevant ones in AI systems, while discarding undesirable behavior: aggression, power-seeking, or sycophancy [389]. This suggests a top-down approach that solves the value alignment problem by grounding it in neuropsychology [229].
In developing NeuroAI for AI safety, an essential goal is to align AIs loss functions with human values. However, achieving alignment does not mean replicating human loss functions exactly. Sarma and Hay [460] and Sarma et al. [461] advocate for a more nuanced understanding of human values through neuropsychology. Their proposed "mammalian value system" approach posits that human values can be decomposed into: mammalian values, human cognition, and the product of human social and cultural evolution. Understanding these components may help develop AI systems that exhibit human-compatible values without directly replicating human biases or limitations.
Furthermore, the right values for an AI system may be different than those of humans. Direct competition within the same niche—whether biological or cognitive—can lead to conflict or dominance by one party, as seen in past evolutionary history [60]. Instead, it’s beneficial for humans and AI to occupy complementary roles in a cooperative ecosystem. By inferring the nuances of human loss functions without duplicating them, we can create AI systems that co-exist with humanity, enhancing resilience and safety [462].
The value of replicating the loss and reward functions of the humans is illustrated by the classic paperclip maximizer thought experiment [22]. In the original thought experiment, a superintelligent AI is tasked with optimizing the manufacture of paper clips. Without any guardrails, the agent proceeds to break everything down into atoms to transform them into paperclips, including the humans who originally built the agent. An agent whose rewards are anchored or derived from the human reward system would likely have very different outcomes. A prosocial agent would be motivated to avoid instilling massive suffering on sentient beings. A safe exploration agent, even if it misunderstood the assignment, would avoid changing the world drastically, because such large and irreversible empowerment is intrinsically dangerous. An agent with homeostatic drives would receive decreasing rewards from turning the world into paperclips, again likely preventing catastrophe.
The challenge, then, is to systematically infer the loss and reward functions of the brain from behavior, structure, and neural data. If we were to correctly identify these, we may be able to obtain safer exploratory behavior from artificial agents; have effective defenses against reward-hacking; imbue agents with human-aligned goals; and obtain robust representations that generalize well out-of-distribution.
Details
Task-driven neural networks across the brain
Task-driven neural networks [140, 463, 464]–sometimes called goal-driven neural networks, or neuroconnectionist approaches–are a commonly used set of tools for comparing representations in brains and artificial systems. In a typical setup, artificial neural networks are trained to perform a task that a brain might accomplish, whether the task is image categorization, a working memory task, or generating complex movements [62, 334, 465, 466, 467, 468, 469]. Representations are compared using a growing suite of methods–linear regression, representational similarity analysis, shape metrics, and dynamic similarity analysis [115, 116, 418, 419]. Frequently, different network architectures, loss functions, and stimulus sets are considered [470]. Under that framework, networks and loss functions that are better at explaining neural data can point us toward how the brain leads to behavior, which may be later verified with causal manipulations [67, 68, 112, 152].
While task-driven neural networks were originally applied to form vision in the ventral visual stream, they have now been extended to the dorsal visual stream, to auditory cortex and language, proprioception, olfaction, motor cortex, the hippocampus, and even cognitive tasks that are dependent on association areas and the frontal lobe (see Box [box-taskdrivennn] for references).
Box: Task-driven neural networks across cortex
The field of task-driven neural networks [140, 463, 464] use deep learning to better understand representation and computation in natural neural networks. Originally applied to form vision in the ventral visual stream, a large number of other areas and phenomena have now been investigated fruitfully using these methods. We list some of these here.
Visual System
Foundational work showed deep CNNs trained on object recognition develop representations matching neural responses throughout the ventral stream, including IT [465, 466]
Later work validated that this could be used for manipulation of neural activity [67, 68, 112]
Unsupervised representations can account for responses in high-level visual cortex [62, 471]
Later work demonstrated similar principles in V1 [91] and V4 [95], as well as the dorsal visual stream [468, 472, 473, 474]
This work has now been extended to more specialized capabilities, including face processing [475], object context [476], visual attention mechanisms [411, 477], predictive processing [478] and letter processing [479]
Auditory Processing
Language
Motor control
Olfactory processing
Chemical recognition networks develop piriform-like representations for odor encoding [489]
The evolution of the organization of olfaction can be replicated using task-driven neural network [490]
Networks trained on masked auto-encoding on chemical structures learn representations similar to humans [491]
Hippocampal formation
Spatial navigation networks develop representations similar to biological circuits, including grid cells [492, 493], place cells [494, 495] and head direction cells [496]
Place cells in the hippocampus compute a predictive map, similar to the Successor Representation used in RL [497], which can be emulated in biologically plausible neural network models [498, 499, 500]
Mapping sequences to cognitive maps reveals links between transformers and the hippocampus [501]
RNN models of planning can explain hippocampal replay [502]
Frontal lobe and executive function
While task-driven neural networks have proven a critical tool in understanding biological neural networks, important gaps remain. Understanding computation in non-sensory, non-motor regions remains difficult [506]. A fundamental bottleneck is the lack of good artificial models for some tasks (e.g. reasoning, [507]). Most models only account for one area rather than a range of areas, although multimodal models have become more popular. While deep ANNs are some of the best current models of neural function, it is not unusual that they account for a small proportion of the relevant variance. Capturing neural and individual variability as well as changes throughout development remain a significant long-term challenge.
Feasibility of identifying loss functions directly from brain data using task-driven neural networks
Task-driven neural networks have proven highly successful at finding links between neural representations in biological systems and artificial neural networks, and in elucidating neural function. We agree with [464] that this “research programme is highly progressive, generating new and otherwise unreachable insights into the workings of the brain”. Here we ask a different question: can task-driven neural networks identify the right loss functions that the brain implements that can be transplanted to make safer AI systems?
A popular practice in the field is to benchmark several artificial neural networks, often trained for engineering purposes, in terms of their similarity to brain representations. This has been used to infer, for example, that deep nets are better aligned to the brain than classical computer vision models [463]; that self-supervised representations are just as capable as less biologically plausible supervised representations at accounting for neural activity in the ventral stream of visual cortex [62]; and that adversarially robust networks are better aligned to brains than non-robust networks [131, 508].
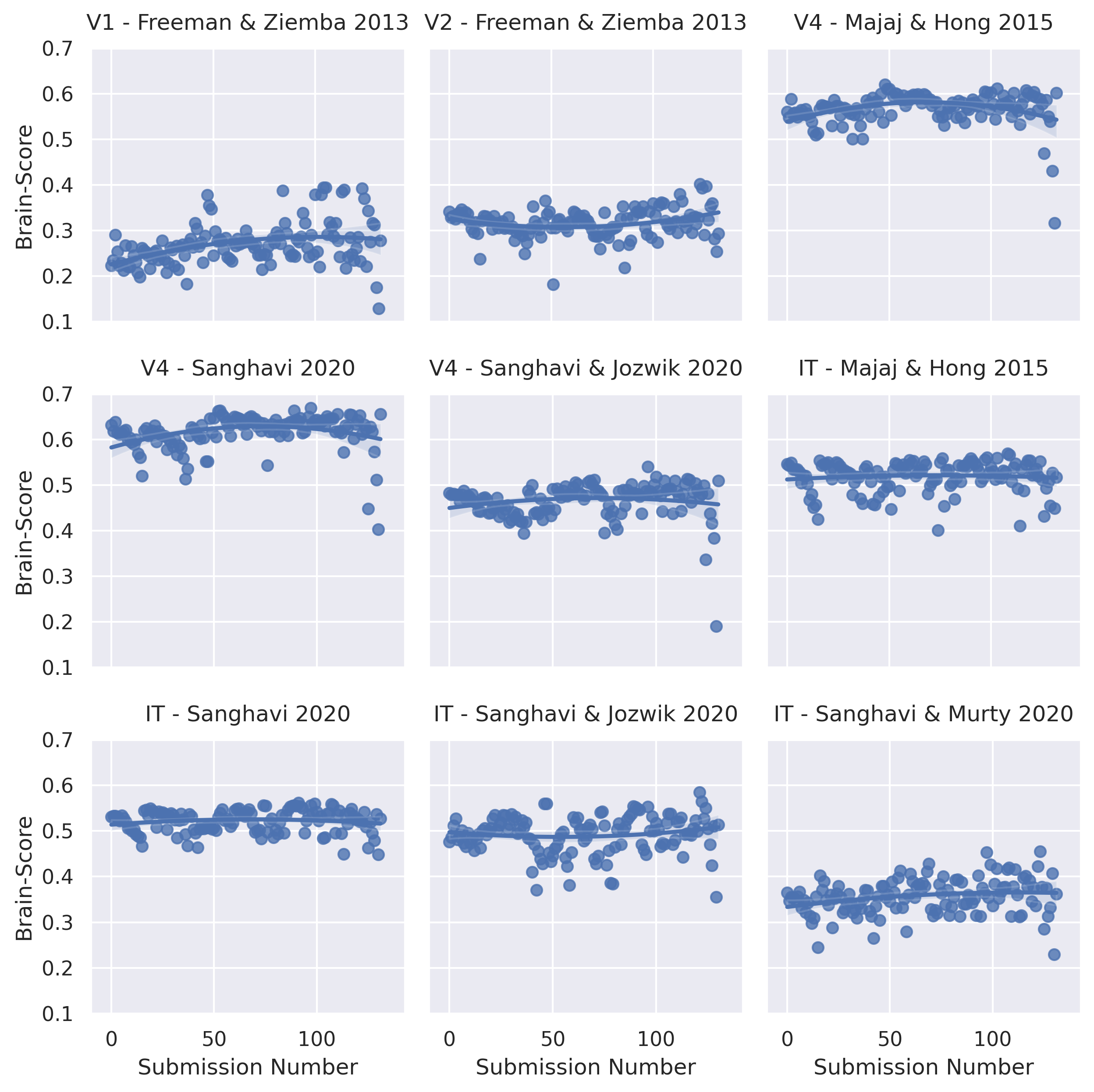
Ideally, benchmark scores should provide a north star that enables hill-climbing, moving slowly but surely toward the right architectures, loss functions, and data regimes that align AI systems with brains. This is one aspiration of BrainScore [509], which seeks to find models that are brain-aligned by benchmarking multiple models against multiple datasets, originally for shape vision in the ventral visual stream, and more recently for language models. It has been noted [510] that supervised image classifications have become less brain-aligned as they have become increasingly proficient at image classification. Here we note a different, but conceptually related finding: visual BrainScores have remained stagnant over the years. Figure 19 plots visual brain scores for 9 different datasets as a function of the submission number, a proxy for the submission date of these models. Unlike many other machine learning benchmarks, where we’ve seen rapid progress and eventual saturation, visual BrainScores have remained quite stable over the past 6 years. These observations are congruent with the fact that neural alignment is only modestly improved with scaling [511].
Why is this? We list three possibilities:
The models are not diverse enough. The benchmarked models all lie within a low-dimensional manifold, converging toward similar representations, and there is insufficient diversity to identify directions in model space which would bring models in closer agreement to brain data [402, 512].
The scores are not very discriminative. [470] use billions of regressions to match vision ANNs to brain data, and find it difficult to infer finer-grained distinctions between loss functions. In the language domain, [513] report that a next-token prediction objective and a German-to-English translation objective lead to representations that are equally good at predicting brain responses to podcasts in unilingual English speakers. They report that “the high performance of these [next token prediction] models should not be construed as positive evidence in support of a theory of predictive coding [...] the prediction task which these [models] attempt to solve is simply one way out of many to discover useful linguistic features”.
The scores are noisy. Seemingly innocuous changes in the evaluation function to discriminate these models can change the relative rankings of these results [514, 515, 516, 517, 518]. Brain scores are often fit in the interpolation regime, where the number of latent weights is far larger than the number of observations. In that regime, scores are a product of the latent dimensionality of the signals and the match of these latent dimensions to the brain, interacting in often unintuitive ways [113, 519, 520].
Taken together, these results point toward a lack of identifiability that prevents us from reverse engineering the objective functions of the brain [521]. With noisy scores lying in a low-dimensional subspace, it is difficult to estimate “gradients” in model space: changes in model parameters, type, or training regimen that would lead to better scores.
How can we improve task-driven neural network methods to better discriminate among different loss functions? We list three potential solutions:
Use more highly discriminative benchmarks. Many of the standard neural benchmarking datasets were collected more than a decade ago, for purposes different than benchmarking. Static benchmarks of the future should be designed from the ground up to unambiguously identify better models on test sets, and contain enough training samples to properly estimate the mapping between ANN and brain representation. Beyond static benchmarks, closed-loop methods [67, 68, 112] and discriminative stimuli [522, 523] can better differentiate models. Benchmarks should cover diverse set of complex real-world cognitive behaviors to capture a large slice of relevant brain representations [326, 327, 328, 329, 330, 331, 332, 333, 334].
Explore a larger portion of the design space of models. Typically, benchmarking focuses mostly on pretrained models which have been trained for engineering purposes, with a handful of bespoke models that supplement those models to test specific hypotheses [62, 468]. Sparse coding [524], local Hebbian losses, predictive coding [525], eigenspectrum decay [526], adversarial training, augmentation with noisy and blurry inputs [48], and other neurally inspired objectives are rarely explored in combination with each other. Neural architecture search, loss function search, and data-centric AI approaches [527] could explore a much larger portion of model space. While these approaches can be quite expensive computationally, leveraging scaling laws to extrapolate from smaller training runs [109, 528] and Bayesian optimization in a closed-loop design [529] could help better explore the space.
Complement in silico benchmarking with physiological experiments. Recent studies in flies have leveraged task-driven neural networks, data-driven modeling, in addition to causal methods to estimate the entire cascade of processing stages that lead to specific behaviors [151, 152]. While these studies have been in part enabled by the publication of a whole-brain connectome, which remains unavailable in mammals, they indicate how one could better infer loss functions using task-driven neural networks in mammals in the future.
Forward and inverse reinforcement learning to infer the brain’s reward function
One of the most celebrated successes of computational neuroscience has been linking reinforcement learning and the reward circuits of the brain [530, 531, 532]. The mesolimbic reward system–the VTA (part of the brainstem), amygdala, and the basal ganglia, including the nucleus accumbens (NAc), caudate nucleus, putamen and substantia nigra (SN)–implement a form of reinforcement learning. A series of foundational studies have demonstrated that dopaminergic neurons in these areas encode reward prediction errors, a central concept in reinforcement learning algorithms [530]. These neurons adjust their firing rates in response to unexpected rewards or omission of expected ones, effectively signaling the difference between expected and actual outcomes [533]. Functional neuroimaging studies in humans have also identified prediction error signals in the ventral striatum and other reward-related brain regions, supporting the cross-species applicability of these findings and their importance in understanding disease [534, 535]. The story of TD learning in the brain has been refined over the years, with the dopamine signaling pathway implicated in model-based reinforcement learning [536], distributional reinforcement learning [537, 538], and encoding multiple reward dimensions [539].
To positively impact AI safety, we’d like to understand the precise mathematical form of the reward function of the brain. The true reward function of the brain differs in important ways from the idealizations often used in linking the brain and RL:
Rewards are internal. In the classic framing of reinforcement learning in the brain, rewards are external–a liquid reward, or a chunk of food that is experimenter-controlled. Ultimately, however, all rewards are internal [540, 541, 542, 543, 544].
Rewards have multiple components. Primary reward is split among many drives [545, 546, 547, 548], e.g. food, water, sleep, sex, parental care, affection, and social recognition, and can be represented distributionally [549]. Byrnes refers to multi-component reward functions as ‘N-entry scorecards’ [550].
Rewards are homeostatic. Many of the intrinsic, primary rewards that humans implement are homeostatic [541, 544]: as more reward is harvested, the stimulus becomes less rewarding, even aversive. This is in contradistinction to conventional reinforcement learning, where rewards are a fixed function of the environment.
Rewards change over a lifetime. Reward functions change across different life stages and social contexts, so we cannot assume a single static reward function, even for one particular person [551].
Primary reward functions interact together in complex ways. Some primary rewards saturate more strongly than others [544]: for example, while water is highly rewarding to a thirsty person, it ceases to be rewarding upon satiety, which may be related to the fact that we cannot effectively store water. Other rewards, like those associated with food, do not reach complete saturation, as we can store fat to satisfy our later energy demands; the wide availability of hyperpalatable foods, together with non-saturating reward for food, has been blamed for the obesity epidemic [552]. It is starting to be possible to identify and trace different components of the ‘N-entry scorecard’ of primary rewards by tracing precisely connections between areas in the brain, which has been done in Drosophila [545], as well as in areas of the mouse brain that regulate social needs [546].
How secondary rewards–those that are not genetically encoded–are bootstrapped from primary rewards is an open question. Primary rewards for food have an interoceptive origin, and include a primary component that senses food calories and fat content, as well as a secondary, orofacial reinforcer; this reinforcer could, presumably, be bootstrapped from taste and smell via temporal difference learning. Similarly, Weber et al. (2024) [544] speculate that secondary rewards (e.g. money) are processed by the same pathways that process non-saturating primary rewards (e.g. food), leaving open the possibility that these rewards are bootstrapped using TD-learning. Money can be exchanged for goods and services, including food, and the rewarding value of food can be transferred to money over time, much like an unconditioned stimulus can be reinforced [553, 554].
How might the brain learn to compute an abstract secondary reward, like cultural or aesthetic values observed from mentors, and compute this cost function internally? A well-characterized example of how the brain represents and computes secondary rewards is in songbirds. Songbirds form a memory of their tutor’s song, which they use to precisely evaluate their own song at a milliseconds timescale while they practice. This evaluation signal can be observed in dopaminergic neurons, which produce bursts of activity when the song sounds better than expected, and dips in activity when it sounds worse than expected [555, 556, 557]. The signal is computed by upstream cortical areas involved in learning the tutor memory, and feeds into reinforcement learning circuits in the basal ganglia [558, 559, 560, 561, 562]. Other types of intrinsic rewards in other species, including humans, may be computed similarly. Specifically, higher-order cortical areas learn to compute specific features of the world, and may transmit this signal to deep-brain dopamine neurons, which interface with evolutionarily ancient reinforcement learning circuits. Thus, throughout evolution, an increased flexibility and expressivity of cortical representations could greatly expand the types of reward functions the brain can learn, from initially only primary rewards, to complex or abstract features learned from others, such as money or aesthetic preferences.
While reward pathways for primary reinforcers like food are relatively well-characterized–they are a prime target for treatments for obesity [563]–other primary reinforcers are poorly understood, including those related to social instincts, recognition, affection, and parental care. Reward functions in adults are ultimately derived from the genome, which bootstraps developmental programs leading to intrinsic reward circuits, which are then refined through interaction with the environment and higher order shaping of internal circuitry. Secondary reward functions are highly contingent on the environment but nevertheless are strongly constrained by the structure of primary rewards. To understand the precise mathematical form of primary and secondary rewards–including their variation across the population–several approaches could be considered:
Decipher the implementation of reward functions through structure-to-function mapping. Building off the successes described above in songbirds at a more granular level would likely require moving to animal models with a full toolkit of brain-mapping and recording technologies, i.e. drosophila and mice. For example, to identify candidate sources of secondary rewards, connectomics approaches could identify specific cortical inputs to dopaminergic areas. To map how the genome impacts reward functions would require large-scale mapping of a diverse set of reward-related behaviors, coupled with large-scale genetic studies. Capturing sufficient dynamic range in this map will likely require a broad distribution of behavioral preferences, likely including non-human animal behaviors and comparative genetics and anatomical studies.
Estimate rewards by backing them out from reward prediction errors measured in the mesolimbic reward circuit. The TD(0) learning rule updates the value function using the reward prediction error, the signal that is conventionally assumed to be carried and reported by neurons in the mesolimbic system [530, 551]. Thus, it may be possible to back out the reward function of the brain without the full machinery of inverse reinforcement learning, although a full solution would need to carefully consider the heterogeneity of signals in the mesolimbic system, their dependence on internal state, and their non-stationary nature [543].
Use inverse reinforcement learning. This is the classic solution to inferring reward from behavior [564]. Several studies have attempted to back out reward functions from animal and human behavior and compare them to brain activity [565, 566, 567, 568, 569, 570, 571, 572]. In general, these studies have not leveraged reward prediction error signals in the mesolimbic reward pathway. Rather, they infer reward functions using classic IRL (e.g. using maximum entropy inverse reinforcement learning) and then compare the retrieved reward functions with other aspects of an animal’s behavior, or their neural activity. The combination of IRL and conditioning on brain data could help alleviate the classical issues with IRL, including the ill-posedness of its inference, and its reliance on assumptions about agent rationality. See [573] for a framework that links RL models of cognitive behavior to biologically plausible models of neural activity. Classic IRL can face feasibility challenges with more complex reward functions, which can be addressed with more structured, hierarchical, symbolic representations of reward functions [574].
While there is a rich body of research on reinforcement learning in the brain, there is surprisingly sparse literature on how intrinsic rewards are coded, with songbirds as a notable exception, as discussed above. Much of the research studying reward processing non-invasively in humans focuses on isolating single mechanisms, for example using the Iowa gambling task, the monetary incentive delay task, 2 armed bandits, etc., and is thus ill-suited to derive intrinsic rewards using brain-conditioned reinforcement learning or inverse reinforcement learning. We believe there is fruitful research to be done by studying decision-making with a high loading on intrinsic rewards under naturalistic scenarios to infer the brain’s true reward functions.
Brain-like AGI safety
In a series of blog posts [55], AI safety researcher Steven Byrnes proposed a pathway toward brain-like AGI safety that partially overlaps with the goals of inferring goals from brains, as well as evolutionary approaches to AI safety. While we cannot fully do justice to their entire proposal here, we outline it for the benefit of neuroscientists who might resonate with the framework but are not exposed to the AI safety literature.
Broadly speaking, the proposal posits the existence of two systems:
A learning subsystem. Includes the neocortex, as well as parts of the striatum, amygdala, and cerebellum. As its name indicates, the learning subsystem’s representations are learned within an organism’s lifetime, from scratch. Byrnes roughly estimates the proportion of the brain dedicated to “from-scratch” learning as 96%. The learning subsystem is the seat of the N-entry scorecard, a term-of-art for a short-term predictor of reward that could be identified with the mesolimbic reward system, especially secondary rewards or multiple reward components. It is also responsible for building a disentangled world model.
A steering subsystem. This includes large parts of the hypothalamus, but also potentially the globus pallidus. The representations in this system are posited to be hardcoded in the genome from birth, although there is some space for low-dimensional, within-lifetime calibration. The steering subsystem’s name echoes evolutionary neuroscience, wherein the common ancestor of modern animals, the worm-like urbilaterian, had a basic nervous system with the capacity to steer toward food and away from enemies, along with a basic memory and motivation system to maintain homeostasis [38, 39, 575, 576]. In the framework of Byrnes, the steering subsystem sends supervisory systems and rewards to the learning subsystem.
A core claim of the brain-like AGI safety framework is that understanding the learning subsystem in adults is the wrong level of abstraction: in adults, structure, and function are far too complex to fathom directly. Rather, we should focus on the training data used within an animal’s lifetime, as well as the underlying learning algorithms that led to these representations. This resonates with the framework of Richards et al. (2019) [140].
By contrast, Byrnes posits that we should focus on the function of the steering subsystem. “All human goals and motivations come ultimately from relatively simple, genetically hardcoded circuits in the Steering Subsystem (hypothalamus and brainstem)”. We should “reverse-engineer some of the “innate drives” in the human Steering Subsystem (hypothalamus & brainstem), particularly the ones that underlie human social and moral intuitions [...], make some edits, and then install those “innate drives” into our AGIs.”. Some of the desirable innate drives include those underlying altruism, cooperation, and a desire to align with human values. This is consistent with the framing in the previous section. Indeed, Byrnes places a high priority on understanding the reward function of the brain, and in particular, how social behaviors are bootstrapped from instincts instantiated in the steering subsystem; in other words, how primary rewards and built-in circuits are bootstrapped to create prosocial behavior.
Because this proposal recapitulates and overlaps substantially with other proposals considered in this roadmap [140, 229], we do not evaluate it separately; rather, we see it as a valuable synthesis and accessible introduction to neuroscience ideas for an AI safety audience.
Evaluation
Inferring the loss functions of the brain presents a promising yet challenging avenue for enhancing AI safety. The idea leverages the potential alignment between human cognitive processes and AI objectives to mitigate risks like reward hacking and misaligned behaviors. However, several significant hurdles exist:
Identifiability issues in inferring loss functions from the brain. The complexity of the brains loss functions and the challenge of uniquely identifying them based on observed data limit the practicality of this approach. Current tools like task-driven neural networks may lack the sensitivity and specificity needed to pinpoint exact loss functions, as evidenced by stagnant brain scores.
Complexity of human reward functions. Human reward functions are likely multifaceted, context-dependent, homeostatic, non-stationary, and influenced by evolutionary factors, making them difficult to model accurately.
Lack of scalability of Inverse Reinforcement Learning (IRL). IRL, one of the most promising approaches to infer reward functions from the brain, is limited to small state spaces under assumptions that likely don’t hold. Brain-conditioned IRL is underexplored for inferring reward functions for the brain.
Limited relevant data on intrinsic rewards, and how they’re used to bootstrap secondary rewards. In cases where this data exists, such as songbirds and drosophila and certain rodent behaviors, it has been highly valuable.
Limited tools for measuring structure-to-function maps to understand how genetic circuits drive development through wiring rules that lead to innate reward functions. Interestingly, recent BRAIN cell atlases show that most of the genetic cell type diversity is in subcortical (likely ‘steering’ regions that represent loss functions in the brain) [577].
Despite these challenges, ongoing advances in neuroscience and AI offer potential pathways to overcome some obstacles. Improved benchmarking methods, exploration of a wider space of models and behaviors, and integrative approaches combining behavioral and neural data could make it more feasible to infer loss functions.
Opportunities
Develop discriminative benchmarks for task-driven neural networks. Create new datasets and evaluation methods designed specifically to differentiate between models based on their alignment with brain data, across a broad range of behavioral contexts, enhancing the ability to infer loss functions.
Conduct closed-loop experiments. Perform closed-loop neural experiments to test specific hypotheses about the brains loss functions, allowing for more precise validation of models.
Explore a wider model space. Investigate a broader range of architectures, loss functions, and learning rules, including those inspired by biological processes like sparse coding and predictive coding.
Integrate multimodal data from a broad range of behavioral contexts. Combine behavioral, neural, and structural data to improve the inference of reward functions, leveraging the strengths of each data type.
Advance IRL. Refine IRL techniques to better handle the complexities of human behavior and integrate neural signals related to reward processing, potentially overcoming identifiability issues.
Focus on evolutionarily ancient drives. Study and model the fundamental drives shared across species to inform the design of AI systems with more universally aligned objectives through comparative neuroanatomy across different mammal species.