NeuroAI for AI Safety
As AI systems become increasingly powerful, the need for safe AI has become more pressing. Humans are an attractive model for AI safety: as the only known agents capable of general intelligence, they perform robustly even under conditions that deviate significantly from prior experiences, explore the world safely, understand pragmatics, and can cooperate to meet their intrinsic goals. Intelligence, when coupled with cooperation and safety mechanisms, can drive sustained progress and well-being. These properties are a function of the architecture of the brain and the learning algorithms it implements. Neuroscience may thus hold important keys to technical AI safety that are currently underexplored and underutilized. In this roadmap, we highlight and critically evaluate several paths toward AI safety inspired by neuroscience: emulating the brain’s representations, information processing, and architecture; building robust sensory and motor systems from imitating brain data and bodies; fine-tuning AI systems on brain data; advancing interpretability using neuroscience methods; and scaling up cognitively-inspired architectures. We make several concrete recommendations for how neuroscience can positively impact AI safety.
Introduction
AI systems have made remarkable advances in fields as diverse as game-playing [1, 2, 3], vision [4, 5], autonomous driving [6], medicine [7], protein folding [8, 9], natural language processing and dialogue [10, 11], mathematics [12], weather forecasting [13, 14] and materials science [15]. The advent of powerful AI has raised concerns about AI risks, ranging from issues with today’s systems like climate impact [16, 17], systematic bias [18, 19], and mass surveillance [20], to future-looking issues like the misuse of powerful AI by malicious agents [21], accidents stemming from the misspecification of objectives [22, 23], catastrophic risk from autonomous systems [24, 25], and race dynamics among AI companies promoting the release of unsafe agents [26].
AI safety is a field of research aimed at developing AI systems that are helpful to humanity, and not harmful. Because AI is a general-purpose technology [27], AI safety research is fundamentally interdisciplinary, cutting across research in computer science and machine learning, mathematics, psychology, economics, law, and social science. Technical AI safety is a subset of AI safety that focuses on finding technical solutions to safety problems, distinguishing it from other areas such as policy work [23].
We can broadly categorize these safety issues into two levels, depending on the capability of AI systems and time horizon:
Immediate safety concerns from today’s prosaic AI systems. By prosaic AI systems, we mean non-autonomous systems with limited capacity. This includes widely deployed systems like large language models and image generators [28], as well as more specialized systems used in medicine, policing, and military applications, among others. Bias, amplification of societal issues like algorithmic policing, unequal access, interference in the political process and climate impacts, and the misuse of generative AI for creating fake content are commonly cited short-term safety concerns [29].
Long-term safety concerns from future agentic AI systems. By agentic AI systems, we mean partially or fully autonomous systems with a broad range of capabilities. This may include future systems with physical embodiments, including robotics, autonomous vehicles, aerial drones and wet-lab autonomous scientists [30], as well as purely digital agents such as virtual agents interacting in sandboxes [31], virtual research assistants [32], virtual scientists [33], and software engineering agents [34, 35]. These future agents, far more capable than current systems, could be far more valuable for society. Yet they also present dual-use concerns, including malicious use by state and non-state agents, use in military applications, organizational risks, as well as the possibility of losing control over advanced agents which pursue objectives and goals that can be harmful for humanity [36]. Highly capable agentic AI systems are sometimes referred to as general-purpose artificial intelligence, or artificial general intelligence (AGI).
Although immediate safety is critical for AI to benefit society [37], our primary focus here is on safety concerns related to future agentic AI. As stated in a recent report chaired by Yoshua Bengio [24]:
“The future of general-purpose AI technology is uncertain, with a wide range of trajectories appearing possible even in the near future, including both very positive and very negative outcomes. But nothing about the future of AI is inevitable.”
Long-term AI safety is a sufficiently important societal problem [25] that it deserves multidisciplinary consideration, including from neuroscientists. In this roadmap, we aim to evaluate and draw a path for how inspiration, data, and tools from neuroscience can positively impact AI safety.
What can a neuroscientist do about AI safety?
Animals navigate, explore, and exploit their environments while maintaining self-preservation. Among these, mammals, birds, and cephalopods exhibit particularly flexible perceptual, motor, and cognitive systems [38] that generalize well to out-of-distribution inputs, meaning they can effectively handle situations or stimuli that differ significantly from what they have previously encountered.
Humans have evolved additional capacities for cooperation and complex social behavior [39], organizing themselves into societies that promote prosocial conduct and discourage harmful actions. These capacities emerge, in part, from the neural architecture of the brain. Evolution has shaped the brain to impose strong constraints on human behavior in order to enable humans to learn from and participate in society. By understanding what those constraints are and how they are implemented, we may be able to transfer those lessons to AI systems. We could build systems that exhibit familiar human-like intelligence, which we have experience dealing with. It follows that studying the brain and understanding the biological basis of this natural alignment is a promising route toward AI safety.
We use the technical framework introduced by Deepmind in 2018 [40] to more concretely categorize how studying the brain could positively impact AI safety (Figure 1).
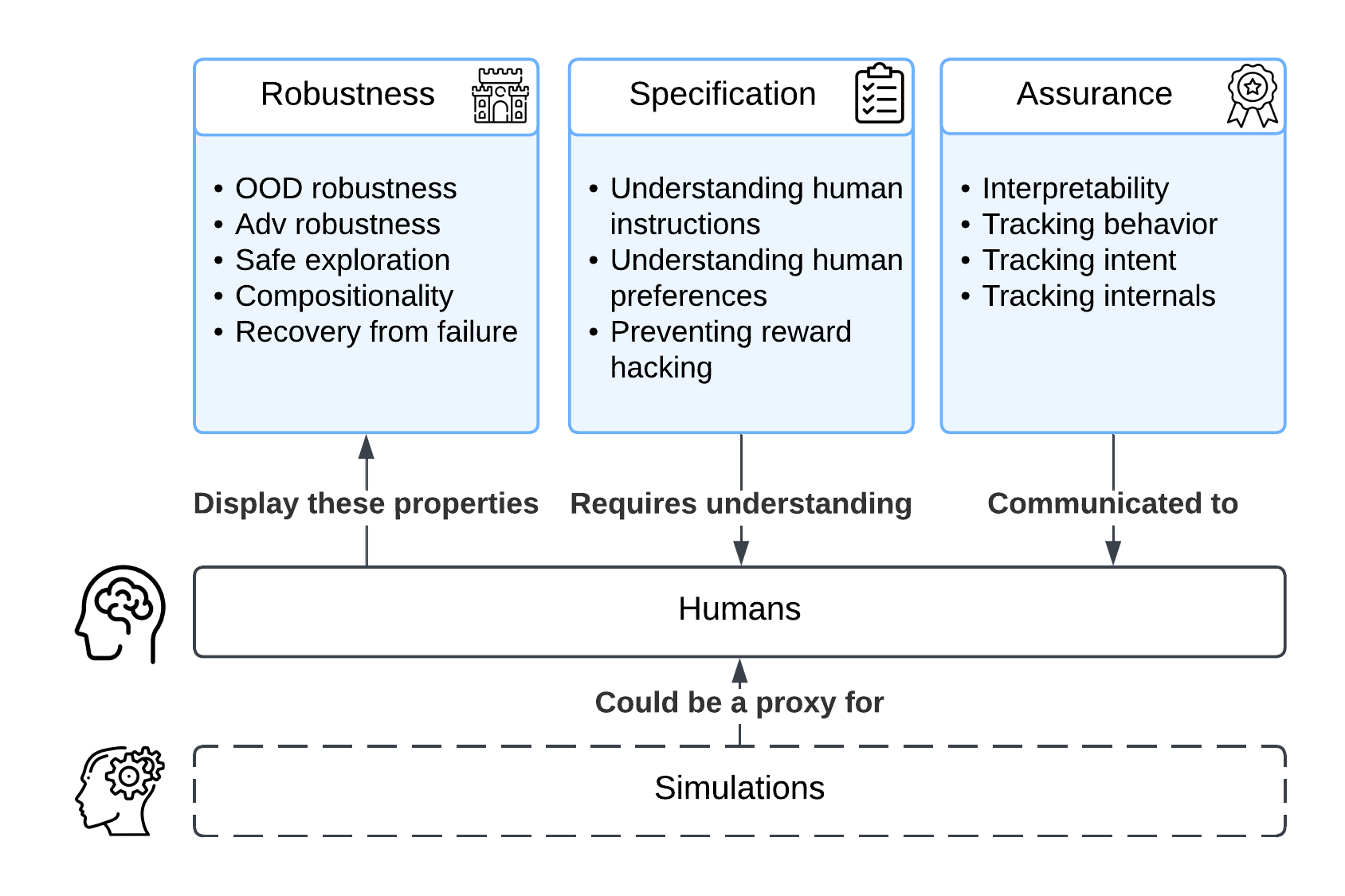
Robustness: specifying how an agent can safely respond to unexpected inputs. This includes performing well or failing gracefully when faced with adversarial and out-of-distribution inputs, and safely exploring in unknown environments. This can also mean learning compositional representations that generalize well out-of-distribution. Robustness further implies knowing what you do not know, by maintaining a representation of uncertainty, to ensure safe and informed decision-making in novel or uncertain scenarios.
Specification: specifying the expected behavior of an AI agent. A pithy way of expressing this is that we want AI systems to “do what we mean, not what we say”. This includes correctly interpreting instructions specified in natural language despite ambiguity; preventing learning shortcuts that generalize poorly [41]; ensuring that agents solve the real task at hand rather than engaging in reward hacking [23] (i.e. Goodhart’s law); and so on.
Assurance (or oversight): being able to verify that AI systems are working as intended. This includes opening the black box of AI systems using interpretability methods; scalably overseeing the deployment of AI systems and detecting unusual or unsafe behavior; or detecting and correcting for bias.
There have been a few examples where neuroscience has already positively impacted AI safety, which fit neatly into this framework. For example, interpretability methods inspired by neuroscientific approaches [42] are a form of assurance, while methods which seek inspiration from the brain to find solutions to adversarial attacks can enhance robustness [43, 44, 45, 46, 47, 48, 49, 50, 51, 52].
Throughout this roadmap, we’ll encounter several more proposals which are aimed at solving specific technical issues within AI safety under one of these rubrics. Some proposals, however–for example, detailed biophysical simulations of the human brain or top-down simulations from representations learned from neural data–seek to benefit AI safety by emulating human minds and all their safety-relevant properties, thus affecting all the relevant rubrics: robustness, specification and assurance. We’ll note them as primarily aiming to build simulations of the human mind in the following.
Box: Marr’s levels for AI safety
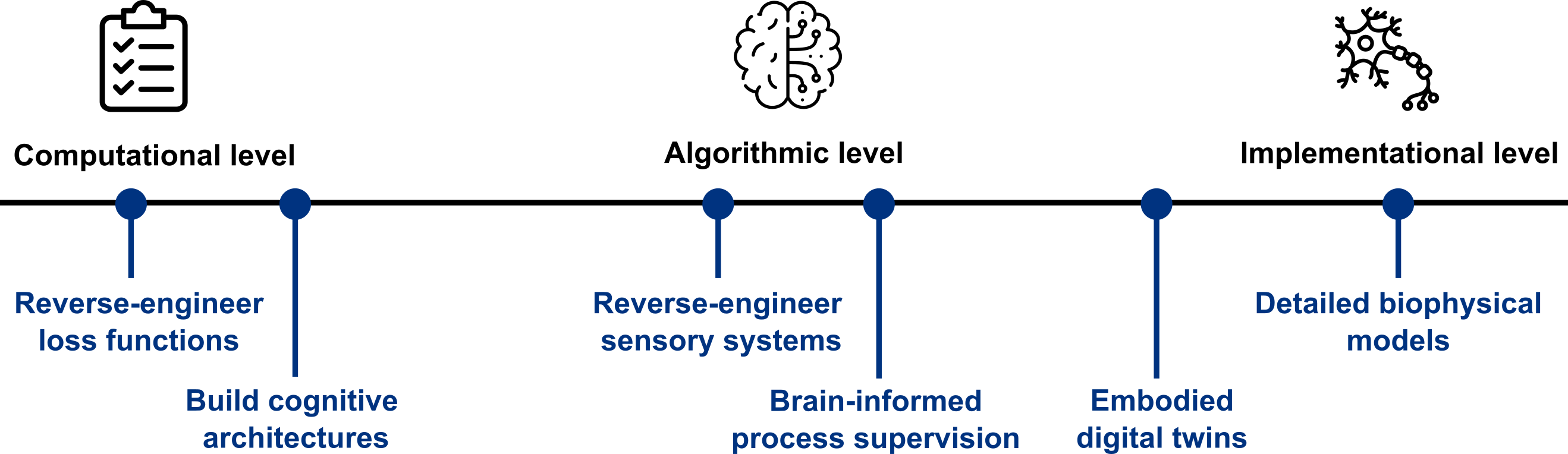
At what level should we study the brain for the purpose of AI safety? The different proposals we evaluate make very different bets on which level of granularity should be the primary focus of study. Marr’s levels [53] codify different levels of granularity in the study of the brain:
The computational level. What is the high-order task that the brain is trying to solve? Reverse engineering the loss functions of the brain and building better cognitive architectures map onto this level.
The algorithmic (or representation) level. What is the algorithm that the brain uses to solve that problem? Alternatively, what are the representations that the brain forms to solve that problem? Approaches including brain-informed process supervision and building digital twins of sensory systems map onto this level.
The implementation level. How is this problem solved by the brain? Biophysically detailed whole-brain simulation falls into that category, while embodied digital twins straddle the algorithmic and implementation levels.
For the purpose of AI safety, any one level is unlikely to be sufficient to fully solve the problem. For example, solving everything at the implementation level using biophysically detailed simulations is likely to be many years out, and computationally highly inefficient. On the other hand, it is very difficult to forecast which properties of the brain are truly critical in enhancing AI safety, and a strong bet on only the computational or algorithmic level may miss crucial details that drive robustness and other desirable properties.
Thus, we advocate for a holistic strategy that bridges all of the relevant levels. Importantly, we focus on scalable approaches anchored in data. All of these levels add constraints to the relevant problem, ultimately forming a safer system.
Proposals for neuroscience for AI safety
There have been several proposals for how neuroscience can positively impact AI safety. These span from emulating the brain’s representations, information processing, and architecture; building robust sensory and motor systems by imitating brain and body structure, activity, and behavior; fine-tuning AI systems on brain data or learning loss functions from it; advancing interpretability using neuroscience methods; and scaling up cognitively-inspired architectures. We list them in Table 1, along with which aspect of AI safety they propose to affect.
| Proposed method | Summary of proposition | Rubric |
|---|---|---|
| Continued from previous page | ||
| Proposed method | Summary of proposition | Rubric |
| Continues on next page | ||
| Reverse-engineer representations of sensory systems | Build models of sensory systems (“sensory digital twins”) which display robustness, reverse engineer them through mechanistic interpretability, and implement these systems in AI | Robustness |
| Build embodied digital twins | Build simulations of brains and bodies by training auto-regressive models on brain activity measurements and behavior, and embody them in virtual environments | Simulation |
| Build biophysically detailed models | Build detailed simulations of brains via measurements of connectomes (structure) and neural activity (function) | Simulation |
| Develop better cognitive architectures | Build better cognitive architectures by scaling up existing Bayesian models of cognition through advances in probabilistic programming and foundation models | Simulation, Assurance |
| Use brain data to finetune AI systems | Finetune AI systems through brain data; align the representational spaces of humans and machines to enable few-shot learning and better out-of-distribution generalization | Specification, Robustness |
| Infer the loss functions of the brain | Learn the brain’s loss and reward functions through a combination of techniques including task-driven neural networks, inverse reinforcement learning, and phylogenetic approaches | Specification |
| Leverage neuroscience-inspired methods for mechanistic interpretability | Leverage methods from neuroscience to open black-box AI systems; bring methods from mechanistic interpretability back to neuroscience to enable a virtuous cycle | Assurance |
Many of these proposals are in embryonic form, often in grey literature–whitepapers, blog posts, and short presentations [54, 55, 56, 57]. Our goal here is to catalog these proposals and flesh them out, putting the field on a more solid ground [58].
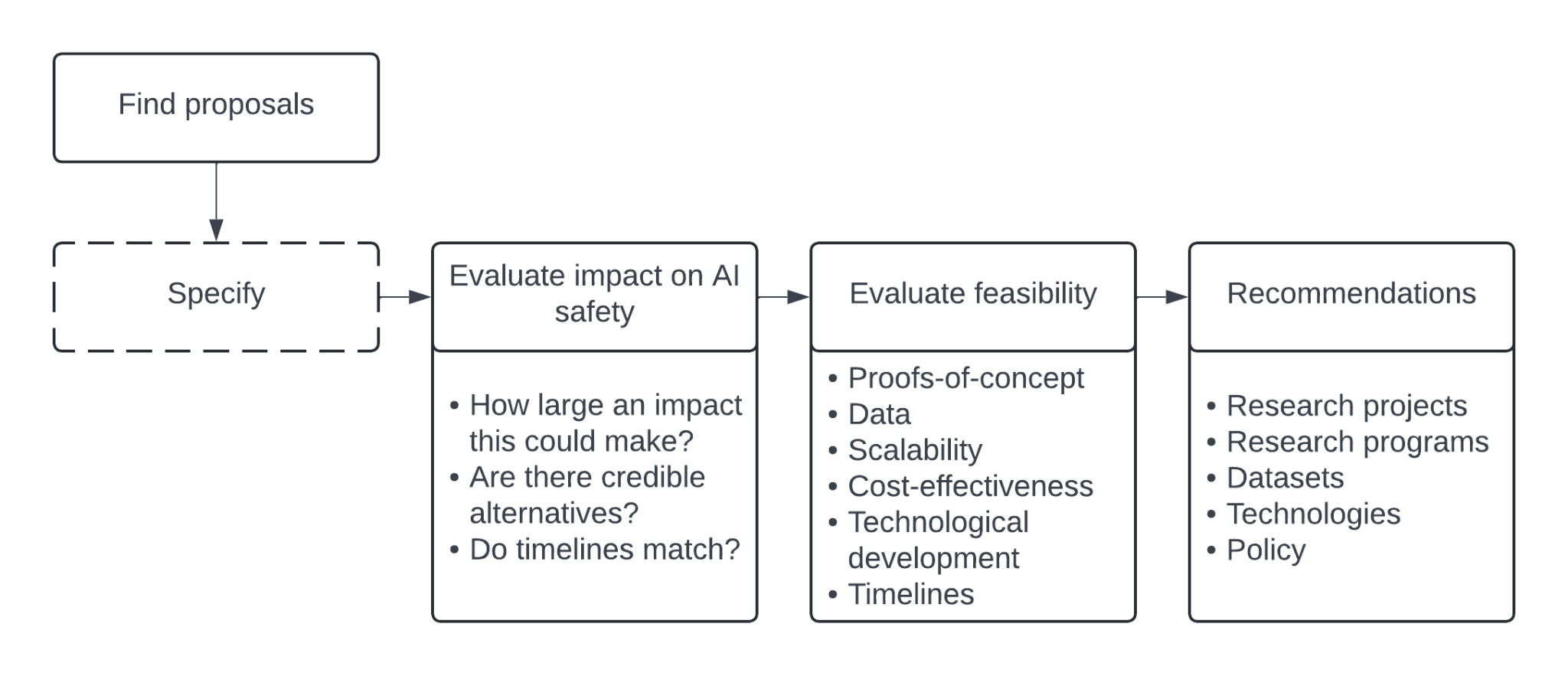
Our process is as follows:
Specify. Give a high-level overview of the approach. Highlight important background information to understand the approach. Where proposals are more at the conceptual level, further specify the proposal at a more granular level to facilitate evaluation.
Evaluate impact. Define the specific AI safety risks this approach could address. Critically evaluate the approach, with a preference toward approaches that positively impact safety while not drastically increasing capability.
Evaluate feasibility. Define technical criteria to make this proposal actionable and operationalizable, including defining tasks, recording capabilities, brain areas, animal models, and data scale necessary to make the proposal work. Evaluate their feasibility.
Recommend. Define the whitespace within that approach, where more research, conceptual frameworks, and tooling are needed to make the proposal actionable. Make recommendations accordingly.
We outline our process in Figure 2. We use a broad definition of neuroscience, which includes high resolution neurophysiology in animals, cognitive approaches leveraging non-invasive human measurements from EEG to fMRI, and purely behavioral cognitive science.
Our audience is two-fold:
Practicing neuroscientists who are curious about contributing or are already contributing to AI research, and whose research could be relevant to AI safety. For this audience, we describe technical directions that they could engage in.
Funders in the AI safety space who are considering neuroscience as an area of interest and concern, and looking for an overview of proposed approaches and frameworks to evaluate them. For this audience, we focus on describing both what’s been done in this space and what yet remains.
Our document is exhaustive, and thus quite long; sections are written to stand alone, and can be read out-of-order depending on one’s interests. We have ordered the sections starting with the most concrete and engineering-driven, supported by extensive technical analysis, and proceed to more conceptual proposals in later sections. We conclude with broad directions for the field, including priorities for funders and scientists.
Box: Are Humans Safe? A Nuanced Approach to AI Safety
The human brain might seem like a counterintuitive model for developing safe AI systems. Our species engages in warfare, exhibits systematic biases, and often fails to cooperate across social boundaries. We display preferences for those who are closer to us–family, political affiliation, gender or race–and our judgment is clouded by heuristics and shortcuts that allow us to be manipulated [59]. Our species name, homo sapiens–wise human–can sometimes feel like a cruel misnomer [60].
Does drawing inspiration from the human brain risk embedding these flaws into AI systems? A naive replication of human neural architecture would indeed reproduce both our strengths and weaknesses. Even selecting an exemplary human mind–say, Gandhi–as a template raises complex philosophical questions about identity, values, and the nature of consciousness, themes extensively explored in science-fiction. As history shows us, exceptional intelligence does not guarantee ethical behavior; in the words of Descartes, "the greatest minds are capable of the greatest vices as well as of the greatest virtues" [61]. Furthermore, pure replication approaches can display unintended behavior if they incorrectly capture physical details or get exposed to different inputs, as twin studies remind us that even genetically identical individuals can have very different life trajectories.
We propose instead a selective approach to studying the brain as a blueprint for safe AI systems. This involves identifying and replicating specific beneficial properties while carefully avoiding known pitfalls. Key features worth emulating include the robustness of our perceptual systems (Section 2) and our capacity for cooperation and theory of mind (Section 5). This approach relies on computational reductionism to isolate and understand these desirable properties.
Such selective replication is most straightforward at computational and algorithmic levels, but implementation-level approaches may also be feasible. Advances in mechanistic interpretability (Section 8) offer promising tools for understanding and steering complex systems, potentially including future whole-brain biophysically detailed models (Section 4), though this remains speculative.
In pursuing neuroscience-inspired approaches to AI safety, we must maintain both scientific rigor and ethical clarity. Not all aspects of human cognition contribute to safety, and some approaches to studying and replicating neural systems could potentially increase rather than decrease risks. Success requires carefully selecting which aspects of human cognition to emulate, guided by well-defined safety objectives and empirical evidence.