NeuroAI for AI Safety
As AI systems become increasingly powerful, the need for safe AI has become more pressing. Humans are an attractive model for AI safety: as the only known agents capable of general intelligence, they perform robustly even under conditions that deviate significantly from prior experiences, explore the world safely, understand pragmatics, and can cooperate to meet their intrinsic goals. Intelligence, when coupled with cooperation and safety mechanisms, can drive sustained progress and well-being. These properties are a function of the architecture of the brain and the learning algorithms it implements. Neuroscience may thus hold important keys to technical AI safety that are currently underexplored and underutilized. In this roadmap, we highlight and critically evaluate several paths toward AI safety inspired by neuroscience: emulating the brain’s representations, information processing, and architecture; building robust sensory and motor systems from imitating brain data and bodies; fine-tuning AI systems on brain data; advancing interpretability using neuroscience methods; and scaling up cognitively-inspired architectures. We make several concrete recommendations for how neuroscience can positively impact AI safety.
Build embodied digital twins
Core idea
In the previous section, we saw a path toward building sensory digital twins that learn the transfer function between sensory inputs and brain state. Could we leverage similar ideas to build a digital twin of the entire brain and body at the functional level? Embodied digital twins aim to model human behavior, embodiment and neural activity at a coarse level without necessarily replicating intricate neural circuits. If they are accurate models of the humans which they aim to imitate, we may derive relevant safety properties from them. This includes the ability to safely explore the world and control their bodies, as well as display the same inductive biases as humans.
An embodied digital twin could be built with a patchwork of approaches: leveraging a pre-existing sensory digital twin; learning a model for the brain and body through self-supervised learning on neural activity and behavior, acting as a base controller; embodying that model in a virtual environment; and fine-tuning the controller in silico in virtual environments. Embodied digital twins would be built with many of the same building blocks as conventional AI systems, which could facilitate synergistic interactions between AI and neuroscience [140]. We evaluate the technical feasibility of embodied digital twins here.
Why does it matter for AI safety and why is neuroscience relevant?
Building a biophysically detailed simulation of people at the brain and body level has long been entertained as a speculative, brute-force path toward artificial general intelligence [22, 54]. In the AI safety community, biophysically detailed bottom-up simulations of neural activity are often termed WBEs–whole brain emulations [22, 54]. Bostrom (2014) lists three reasons why biophysically detailed simulations are a safer path to AGI than alternatives:
Mutual understanding. Because simulations are derived from humans, with whom we have extensive experience, we should be able to reason about their behavior, in the same way we leverage theory-of-mind and empathy to reason about humans. Furthermore, they should be able to reason about humans.
Inheriting human values. Because simulations are derived from humans, they should have similar motivations and values as humans.
Slower takeoff. Because biophysically detailed simulation is a brute-force approach to AGI, it requires massive investments in neural recording and scanning hardware. We should be better able to forecast when biophysically detailed simulations are likely to arrive and prepare accordingly, compared with alternative paths which could be massively accelerated through scientific insight.
It’s easy to find flaws in each of these lines of reasoning. We may not be able to reason about simulations that are run at much faster speeds than humans. Inheriting human motivations and values can be a double-edged sword, as these may include undesirable properties like aggression and power-seeking. And takeoff could be faster than anticipated if coarser-grained simulations can accelerate subsequent steps in building the next generation of simulations.
However, simulations need only be relatively safer than alternative paths toward artificial general intelligence for them to represent an improvement over the status quo [141]. Other desirable properties of human brains that simulations could inherit include the ability to cooperate, theory of mind, and out-of-distribution robustness. Economists have fleshed out how a society with human emulations would function [142]. A recent workshop identified emulation as potentially the most impactful neuroscience-related approach to AI safety, yet it also identified it as the least technically feasible [57].
This state of affairs–high impact, but low feasibility–has motivated some to look for more tractable alternatives. To a certain extent, large language models (LLMs) are a proof-of-existence that imitation learning of human behavior followed by fine-tuning can display emergent capabilities [11]. Could imitating neural data, body and behavior lead to an effective simulation of human capabilities and safety properties, thus leading to an alternative path toward highly capable AI? Embodied digital twins describes brain and body simulations learned through imitation learning of brain data and behavior. In the following, we define the technical challenge in building an embodied digital twin, defining its scope and associated success criteria.
Details
What do we mean by an embodied digital twin? In a footnote, Bostrom and Sandberg [54] define an effective simulation of an embodied nervous system as being able to predict the future state of the brain and body \(x(t)\) at all future times \(t > T_0\) given the state of the system at the current time, \(x(T_0)\), within an \(\epsilon\) bound. The state can be defined at different levels of abstractions, but can include:
Neural activity, e.g. membrane voltage or spike rate
Auxiliary state variables related to neural activity, e.g. a neuron’s relative refractory state, the state of neuromodulators, etc.
The position of the limbs, the load on each muscle, and their velocity; collectively, behavior
The system’s connectome, reflecting the accumulated memories of the organism
An alternative implementation conditions the simulation not just on the current time step \(T_0\) but on several time steps in the past \(t \le T_0\), which is attractive from the point of view of Takens’ theorem [143].
By that yardstick, both embodied digital twins and biophysically detailed models attempt to build simulations of the brain and body at different levels of granularity. An embodied digital twin primarily leverages behavior, functional neural recordings and body measurements to build a simulation from the top-down, while a biophysically detailed model primarily leverages structural recordings and detailed biophysical modeling to build a simulation from the bottom-up.
Several recent proposals and papers help clarify what an embodied digital twin might look like:
AI animal models and the embodied Turing Test
Zador et al. [144] propose to build a simulation of an entire animal in silico–an AI animal model. Comparisons between real and virtual animals would provide a readout of how well a simulation performs. A virtual animal would pass the ’embodied Turing test’ if it is indistinguishable from its living counterpart when observed in a virtual environment.
The virtual rat
Merel et al. [145] demonstrated that training a virtual rat using reinforcement learning in a virtual environment could display rich behavior. Aldarondo, et al. [146] trained an ANN to actuate a biomechanical model of a more advanced version of this virtual rat. When the virtual agent was tasked with imitating real rats, activations in the ANN showed striking similarities with neural activations in the control circuits of the real rats.
The virtual fly
Recent advances in Drosophila connectomics [147, 148] enable simulation of its entire nervous system (130K brain neurons plus 15K in the ventral nerve cord). While some groups pursue direct numerical simulation of this nervous system [149] with detailed sensorimotor integration [150], others take a functional view, virtualizing sensory systems in simplified virtual environments [151, 152].
The virtual C. elegans
With its fully mapped 300-neuron connectome [153], C. elegans offers a unique testbed for contrasting simulation approaches [154]. Biophysically detailed models could implement leaky-integrate-and-fire neurons constrained by the connectome and neural recordings, while a proposed embodied digital twin uses transformers to predict neural activity and behavior from past observations [155].
Note the central role of body simulations in these recent approaches. Neural circuits evolved for sensorimotor control–enabling predation, escape, and survival–must solve computational problems fundamental to general intelligence: generalization across domains, continual learning without catastrophic forgetting, and translating abstract plans into concrete actions. Human-level intelligence likely emerged by co-opting these ancient sensorimotor control circuits [156].
The recent efforts that we list point toward common themes in embodied digital twins: predicting next-step neural activity from the past; virtualizing the bodies of animals; virtualizing the senses of animals; and complementing bottom-up reconstructions of neural activity with virtual training. We turn our attention to each of these in turn.
Foundation models for neuroscience
A key artifact for an embodied digital twin is building a model that predicts the future state of a neural system conditioned on past observations. This naturally links to current state-of-the-art models for text generation [10, 157, 158]: black box models, like transformers or state-space models (SSMs), which are trained to autoregressively predict the future, and can be used as generative models. Building on this naturally allows one to leverage the rich literature and accumulated wisdom on training and fine-tuning foundation models [159], as well as capable software for training ANNs at a large scale [160].
A growing literature in neuroscience aims to accomplish an analogous task: finding good representations of neural activity [161]. Powerful models, trained through supervised, self-supervised or unsupervised learning, can learn effective representations of neural activity [138, 162, 163, 164, 165, 166, 167]. These models have become an integral part of the toolkit of systems neuroscience, allowing one, for example, to estimate single-trial spike rates from noisy neural data. Foundation models for neuroscience, built on generic architectures like transformers, continue this tradition, pretraining large-scale models that find good generic representations of neural activity, which may be used for downstream tasks [161]. Models trained with causal masking or as autoencoders can be used to simulate neural activity.
Several promising models of this flavor have been recently demonstrated for spikes [165], binned spikes [163, 166], fMRI [168], iEEG [169], ECG [170], EEG [171], MEG [172] and EMG [173]. These models face challenges unique to neural data, including registration, alignment, tokenization, and discretization, which have been met in increasingly sophisticated ways. Several recent manuscripts have demonstrated the classic signature of scaling laws: linear improvements in performance with exponential increases in data size.
Building autoregressive foundation models for neuroscience thus relies on:
Getting access to abundant neural and behavioral data (Box [box-available-neural-data]) to train large-scale models
Finding good schemes to curate, filter, embed, register, align, and tokenize the data
Training foundation models with generic models to predict activity in the future using next-token prediction or a related criterion
Evaluating the autoregressive predictive model using suitable criteria
Box: Availability of neural data to train a large-scale model
The past decade has seen an explosion in the quantity of neural data freely available online. These public datasets represent a unique opportunity to learn good representations of neural data for a variety of downstream tasks, including brain-computer interfaces, clinical diagnoses for computational psychiatry and sleep disorders, and basic neuroscience.
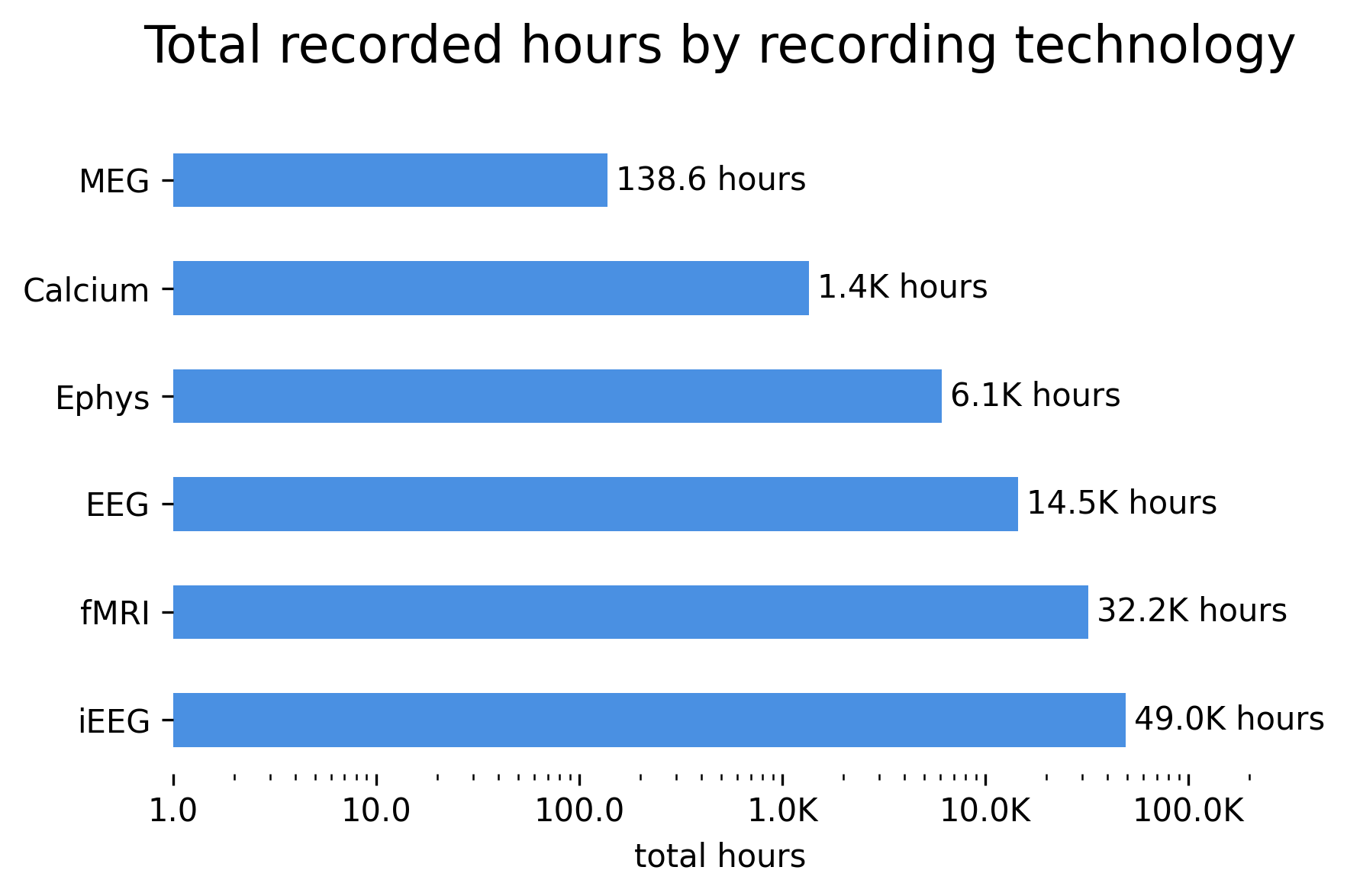
Here we present a breakdown of the available data sources from an analysis of the contents of DANDI, OpenNeuro, iEEG.org, as well as large-scale individual datasets. Some of the highlights from this analysis include:
There are around 100,000 hours of neural data available in freely accessible archives.
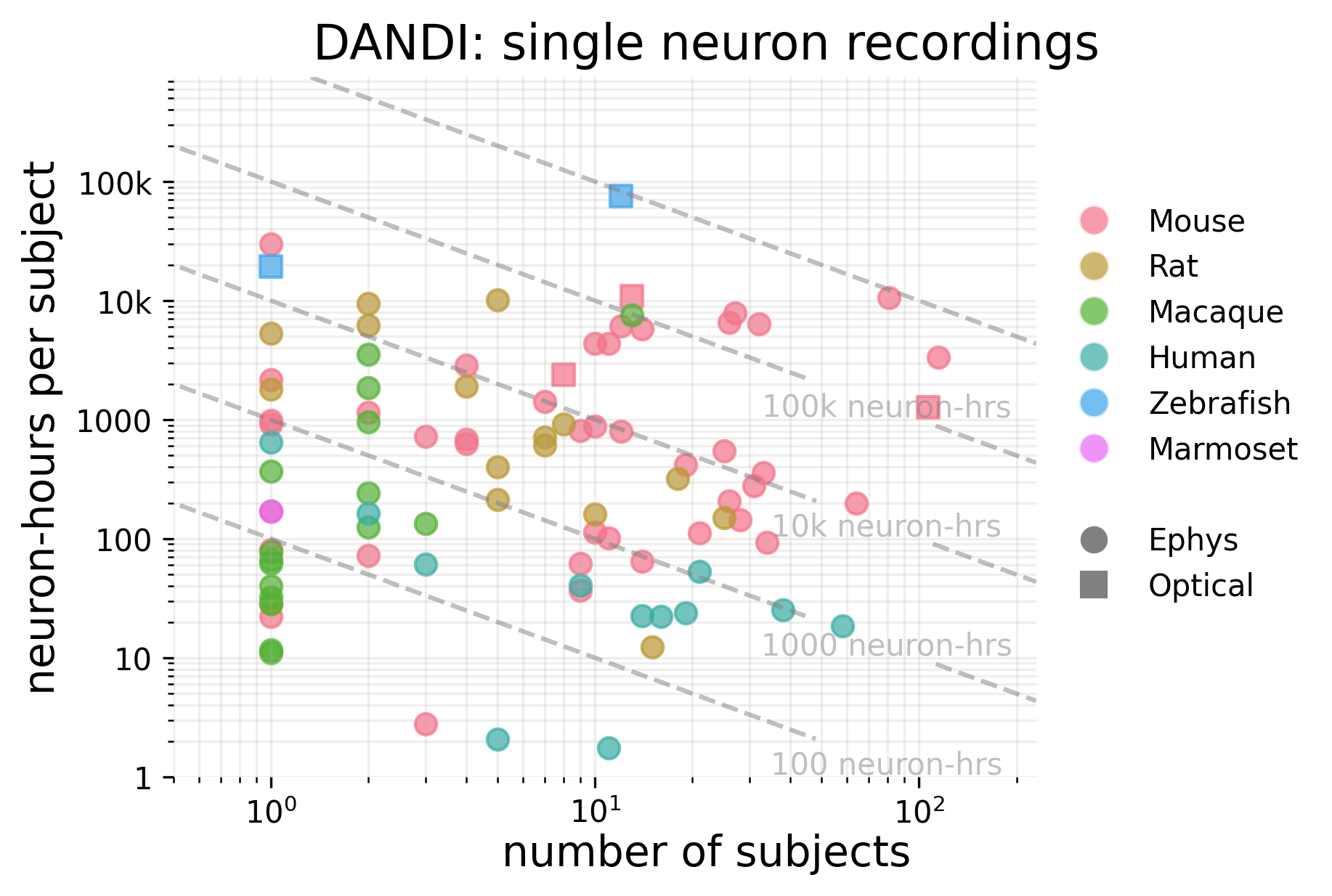
There are roughly 3.3 million neuron-hours of single-neuron recordings from animals.
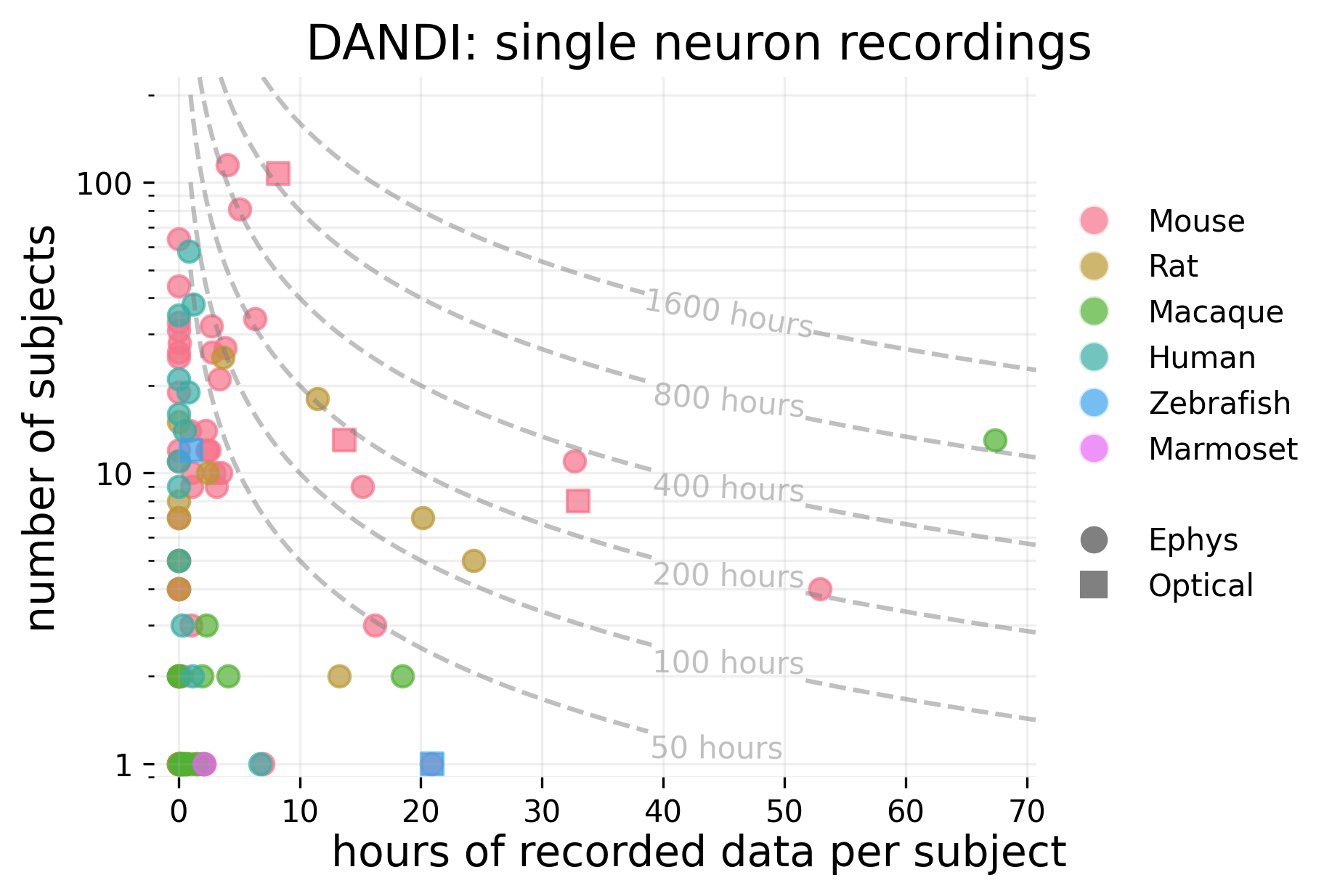
The most abundant data type in terms of number of hours is intracortical EEG in humans–an invasive modality generated from the typically continuous, week-long recordings performed during epilepsy monitoring.
Single neuron data is concentrated in a few datasets; the top 10 largest datasets in terms of neuron-hours account for more than 94% of total neuron-hours across all of DANDI. These come mostly from zebrafish and mouse, with one dataset from macaques.
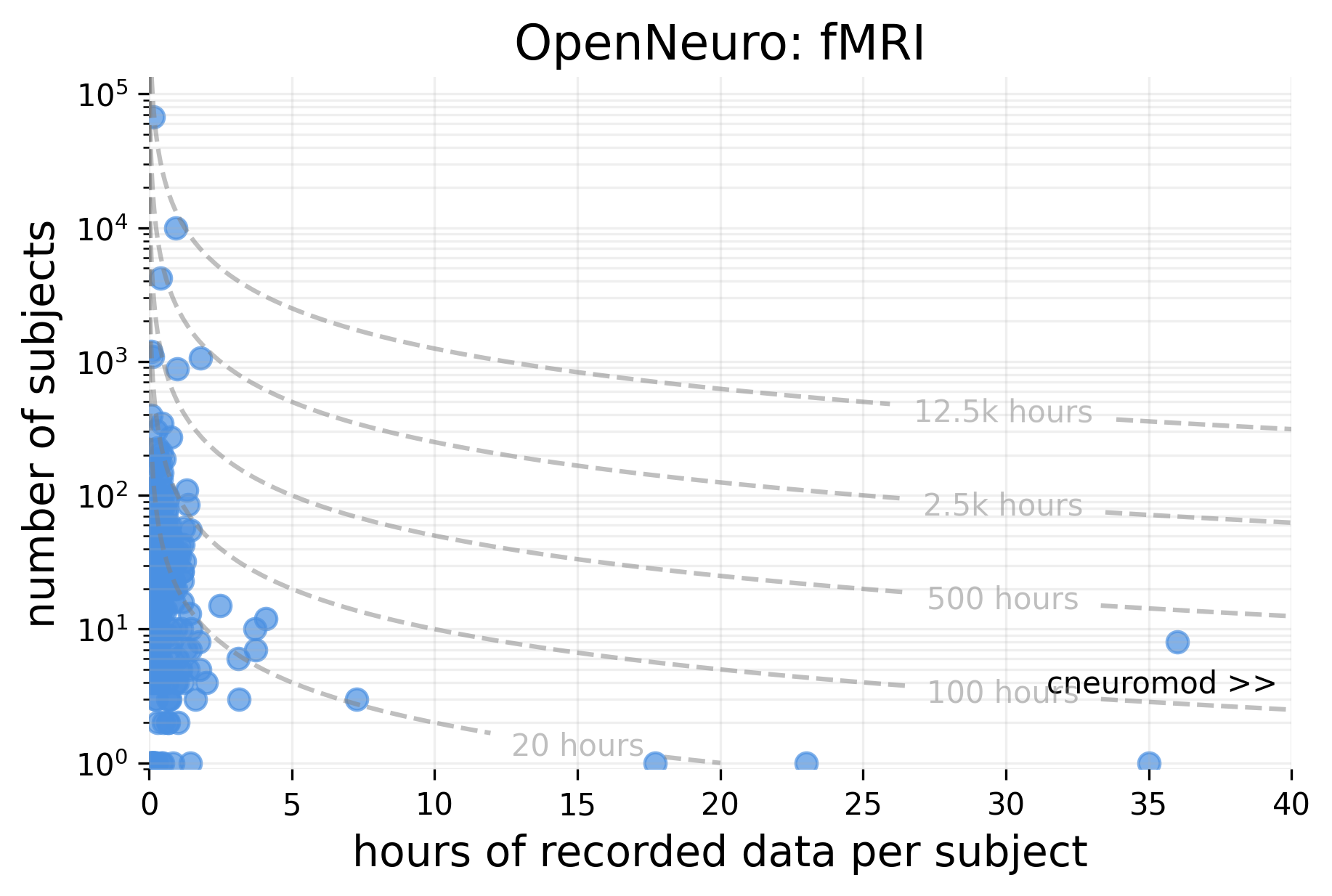
Large fMRI recordings are split into two categories: broad neuroimaging surveys, including HCP and UK Biobank, which scan many people for a short time; and intensive neuroimaging datasets [174], including Courtois Neuromod and the Natural Scenes Dataset, which scan few people for a very long time.
Notably, many unimodal foundation models in neuroscience use a significant proportion of the openly available data [170, 175, 176, 177]. For some modalities, progress will rely on unearthing existing, closed datasets; acquiring new datasets; algorithmic improvements [178]; and stitching data from multiple modalities together. Ideal datasets should leverage high-entropy stimuli and behavior and measure responses across sensory and motor domains to learn good foundation models of the brain.
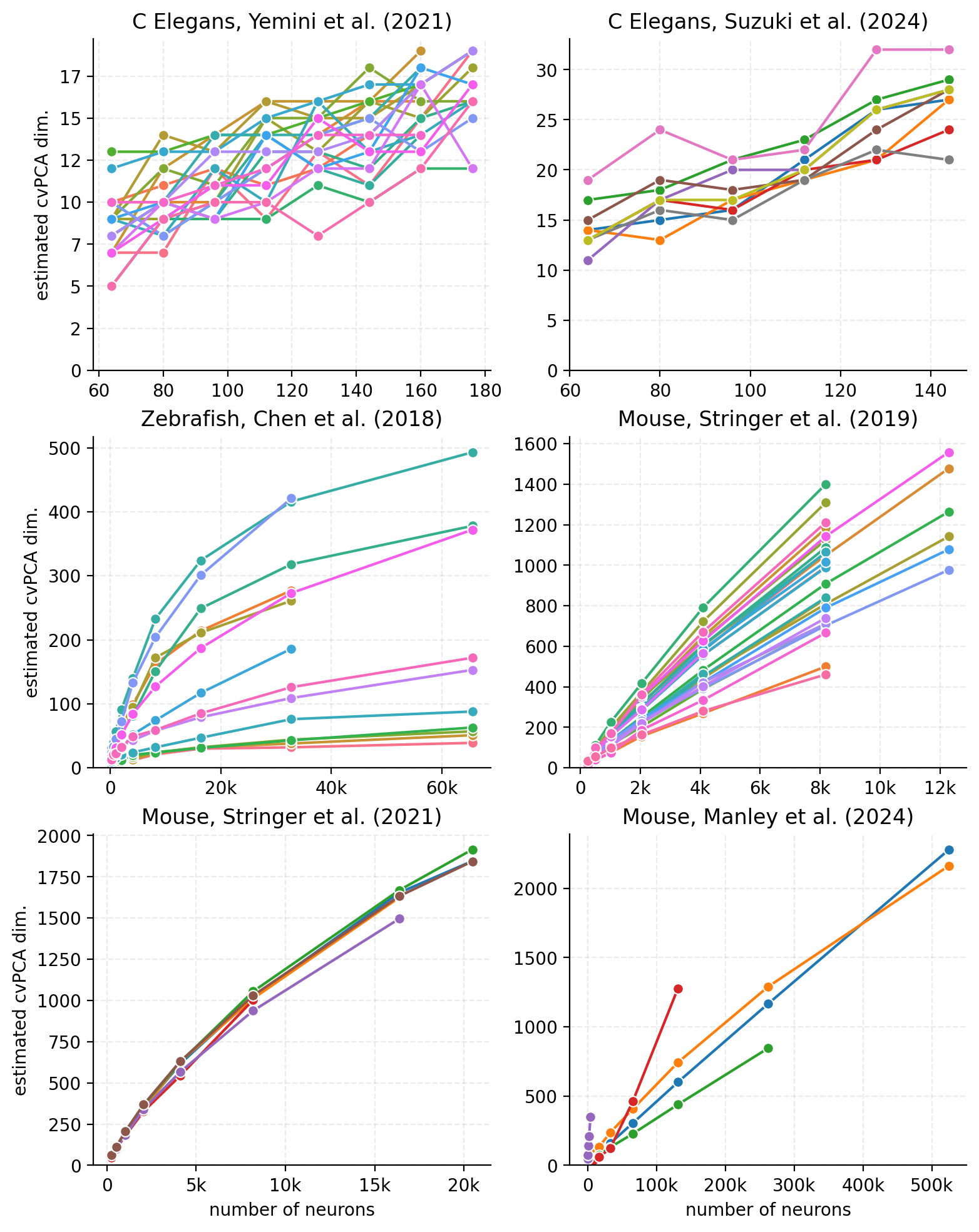
In addition to the sheer size of datasets, we must also consider their quality. Coverage, the percentage of an animal’s neural activity that is recorded, is a critical metric. Currently, we can capture a large proportion of the activity on single neurons in vivo for C. elegans [179] and zebrafish [180] , but this is a challenge for other model organisms. Thus, foundation models of species of interest–including rodents, primates, and ultimately humans–may rely on stitching the activity from many sparse neural activity recordings into an overarching brain simulation. Helpfully, neural activity is of a lower dimension than the number of distinct neurons in the brain [181, 182], but the dimensionality of neural activity remains an unresolved question [139, 183]. This measure is also likely to vary across modalities and depend on the task being represented. We analyze the dimensionality of neural activity across different model organisms in Box [box-neural-dim], an important constraint in designing sparse neural recording systems.
Box: Dimensionality of neural data across model organisms
How high dimensional is neural activity? This is an important quantity as we seek to emulate it. Higher dimensional neural activity requires higher capacity networks to fully capture. How dimensionality scales affects the minimum number of neurons we need to sample from to fully capture the brain. The ideal scenario, of course, is to capture every neuron; but simple extrapolation of scaling trends in neural recording (see Box [box-scaling-trends]) would predict this capacity will not become feasible over relevant AI safety timelines. Therefore, we must currently rely on subsampling, hoping that the captured activity is representative of the neural system as a whole.
We estimated the dimensionality of neural activity in three model organisms based on previously recorded data: C. elegans, zebrafish, and mouse. We used SVCA [139, 183, 184], a metric which estimates the robustly measured number of principal components in neural data (see Methods for details).
Paper Organism Behavior Recording tech [185] C. elegans Chemical sensing Calcium imaging [186] C. elegans Spontaneous Calcium imaging [187] Larval zebrafish Visual stimuli Calcium imaging [183] Mouse Visual processing, spontaneous Calcium imaging, Neuropixels [188] Mouse Visual discrimination, processing Calcium imaging, Neuropixels [139] Mouse Spontaneous Calcium imaging (light bead microscopy) Of note, all estimates of dimensionality tend to follow a power law as a function of the number of measured neurons. Using a simple linear regression estimator in log-log space, we find estimates of the exponent ranging from 0.5 for [187] to 0.91 for [183]. The total number of dimensions measured is undoubtedly limited by the richness of the behavior and stimuli [181], as well as the number of timesteps used for the estimation.
With these caveats in mind, the number of well-estimated dimensions in neural activity is always far lower than the number of neurons–roughly 30 for C. elegans (10% of the number of neurons), hundreds in zebrafish (<.1% of neurons), and, by extrapolation, anywhere between ~10k [139] to ~1M [183] in mice. The spread in the range of estimates in mice is notable; we speculate this is likely a difference between spontaneous and sensory-driven activity. This might be grounds for using different strategies to build predictive models in sensory cortex (e.g. digital twins for the visual system) vs. elsewhere in the brain (e.g. autoregressive models).
Virtualizing animals
While autoregressive models of neural activity–foundation models for neuroscience–are instrumental in advancing embodied digital twins, they are not sufficient. These models predict future neural states based on past neural activity and exogenous inputs, neglecting the critical feedback loops between the organisms behavior, the environment, and subsequent sensory inputs [189, 190]. To fully capture the causal relationship between an organism and its environment, we need to simulate how brain states affect the body, how the body interacts with the world, and how environmental changes influence sensory inputs. In other words, we need to embed autoregressive models in virtual bodies and learn to control virtual animal bodies in virtual environments [144].
Several key enabling technologies are now available to construct virtual bodies and lift them into real-time simulations. Biophysically detailed models–bones, joints, muscles, neuromuscular junctions, and proprioception–have been developed through cadaver studies, light-sheet microscopy, and micro-CT scans. Tools like Blender can be used to edit and simplify raw anatomical data. Models of varying detail and coverage–ranging from a single limb to a whole body–exist for multiple species, including in C. elegans [191], drosophila [150, 192], larval zebrafish [193], mice [194, 195, 196], rats [145, 146], macaques [197] and humans [198]. A popular route is to build a 3D model that can be simplified and calibrated for use in the MuJoCo physics simulator [198, 199]. There is an ongoing trend to move toward more precise models than those derived from cadaver studies by using detailed scans of bodies [150, 196].
The exact level of biophysical detail needed to capture the relevant properties depends on the end-goal of the simulation. For example, modeling forearm movement can be done fruitfully with a highly abstracted and fully differentiable effector model of the arm [200], or with a more biophysically accurate musculoskeletal model [197]. On the other hand, a model suitable for grasp may need to model the soft body physics of the hand [201]. The endpoint of these efforts may be zoos of detailed off-the-shelf biomechanical models at different levels of granularity for use in physics engines that serve as distillations of ongoing data collection efforts.
Virtual bodies with appropriate, hand-designed controllers can be run in a physics simulation engine [202]. Alternatively, controllers may be trained through reinforcement learning [146], for example training a virtual animal to successfully remember and navigate towards reward [145] or navigating through a valley [150]. To lift real animals into a virtual environment, the poses of real animals can be inferred using single- or multiple-view pose estimation software such as DeepLabCut [203], Anipose [204], SLEAP [205], or DANNCE [206]. The poses and movements of virtual animals can then be optimized to match those of real animals, thus effectively virtualizing the animal. Beyond the animal, the environments in which they operate can be virtualized using a combination of 3d modeling and rapidly improving computer vision methods such as photogrammetry, neural radiance fields [207] or Gaussian splatting [208].
Senses can be virtualized at different levels of granularity. For example, to virtualize a drosophila’s sense of sight, one may obtain a coarse approximation by placing a virtual camera lens where the fly’s eyes lie. With sufficiently accurate tracking, it’s possible to approximate, in a virtual environment, what a fly must have seen [152]. A more detailed simulation could simulate the hexagonal layout of the ommatidia [151] or the specific properties of the lens; a fine-grained simulation could leverage a detailed digital twin of the eye [209, 210]. Similar approaches could be taken for other sensory modalities, such as audition. Other important senses remain challenging to digitize. For example, whisking (touch) is a dominant sense in rodents that currently requires either high-framerate videography or optoelectronic tracking [211] to accurately track the flexible whiskers, let alone the forces at the base of the whisker; this is challenging in free behavior [212]. Olfaction is another important sense that is technically challenging to virtualize [213]. Proprioception is important to virtualize, as stable and robust movement require sensory feedback. Proprioception can be simulated elegantly with biomechanical models that have mapped the locations and encoding properties of sensory receptors on the body [214, 215].
Bridging the causal and real-to-sim gap
Even with observational data from brains and behavior, as well as virtual bodies, measurements can only offer partial observations of a system. Not all neurons can be recorded simultaneously, and those that are recorded may not capture all the relevant neural dynamics. Simulations of completely transparent neural networks that implement the functions of interest, e.g., sensorimotor control of complex bodies, can help guide us on how to best sample from real brains [216] and capture the posture and movement of bodies.
A related issue is that datasets rarely cover all possible situations or behaviors an organism can exhibit. Just as we have seen with self-driving cars, rare but critical scenarios might be underrepresented, leading models to fail in unanticipated ways [217]. Since graceful out-of-distribution failure is one of the desiderata of safe AI systems, the generalizability and robustness of embodied digital twins are critical. Several groups have demonstrated empirical results that show that more constraints–e.g. using higher entropy data or constraining the data to be consistent with a connectome [218]–lead to more robust generalization. A mathematically precise theory of the stability of simulations, however, is currently lacking.
One avenue toward better generalization is to build causal models of neural activity [219, 220]. Researchers have begun to explore this approach with C. elegans [154], stimulating all neurons and measuring the resulting outputs, in an effort to characterize neural dynamics and behavior. Unlike models that build a regressor from observational data–which can confound cause and effect–these approaches predict how neural activity and behavior is causally related to changes in the organism’s senses or neural activity. While this is a promising direction, applying causal analysis to larger organisms is highly non-trivial.
Even in the best of circumstances, we will likely need to deal with a sim-to-real gap [221]: the virtual environment can never fully replicate the real world, leading to discrepancies in simulated sensory inputs and motor outputs. To mitigate this, models can be adapted or fine-tuned within the virtual environment. This may involve training the virtual animal through supervised learning, imitation learning, or reinforcement learning to perform tasks that are underrepresented in the observational data. This is conceptually similar to the route by which LLMs are built for chat: pretraining, supervised fine-tuning, and reinforcement learning from human feedback [222]. Designing appropriate training curricula will be essential to expose the model to a wide range of scenarios, improving its robustness and generalizability.
Defining success criteria for embodied digital twins
How would we know if we achieved success in building an embodied digital twin? One possibility, taking a page from Bostrom & Sandberg, is to use autoregressive prediction as a target. For instance, we could measure a real animal’s behavior and neural activity, virtualize the animal, and predict, in the virtual environment, its future activity conditioned on the past [146]. Appropriate metrics could include, e.g. root-mean-square error (RMSE) in predicting the position and angles of the limbs, or the neural activity.
While this straightforward approach seems intuitively appealing, it has some significant drawbacks. There are many reasons why a simulation could fail on a metric basis, not all of which are due to model failure. This includes the difficulty in digitizing the animal and its environment with perfect accuracy, as well as the fact that the systems to be simulated sit at the edge of chaos [223]. These could lead to the divergence of even very capable models. Like the weather, neural activity and behavior might not be predictable in the RMSE sense over a long time horizon [224].
However, much like we can both predict the weather at short time scales and the climate at long time scales, we may be able to simulate neural activity autoregressively at short timescales and the “neural climate” at longer time scales. Appropriate metrics for long-term predictions differ from those for short-time scales, taking into account the entire distribution of predictions and observations. KL divergence between smoothed state spaces [225], neural geometry [115], and dynamic similarity [226] have been proposed. Other relevant metrics may be constructed by taking a page from the evaluation of generative models. For example, the Frechet Inception distance measures both the quality and the diversity of generated images [227].
An alternative approach to long-term behavior evaluation is the embodied Turing test [144]. The assay, judged by a human discriminator, is a test of the “behavioral climate” of a virtual animal. It does not ask whether, for example, a virtual beaver simulation is doing exactly what the real beaver will do given what it did a day ago; it asks whether the beaver’s behavior is within distribution and representative of what real beavers do. Automating the test or finding alternative objective operationalizations will be a key enabling factor in evaluating simulations of animals at the behavioral and neural levels. Synthetic judges built from human or conspecific judgments could be used to scale up evaluation [228], although precautions are needed to prevent Goodhart’s law. An important implicit guardrail of the embodied Turing test is its focus on out-of-distribution evaluation: measuring the behavior of virtual animals in a range of environments, not just the ones where they were originally trained.
Finally, a well-designed evaluation of an embodied digital twin should test whether it displays intelligent behavior. That means verifying that the virtual simulation learns or fails to learn; how it generalizes, transfers or suffers from interference across tasks; how its behavior is affected by training curricula; and so on. One would want to design a series of tests of adaptive behavior, a virtual gym, to put the virtual animals and humans through their paces.
Evaluation
Embodied digital twins intersect with multiple ongoing trends in neuroscience and AI:
Foundation models: training large-scale models for autoregressive generation
Foundation models for neuroscience: training foundation models specifically on neuroscientific data, to create predictive models useful for health applications or basic science
Large-scale naturalistic neuroscience: measuring the activity of a significant proportion of the neurons in a single animal during natural, possibly social behavior
Embodied neuroAI: focusing on the interaction between the environment and the body to understand the mind
Thus, we expect to see considerable progress in embodied digital twins over the next few years as data collection and the application of large-scale modeling in neuroscience continue to scale.
The usefulness of embodied digital twins for AI safety hinges on assumptions that are difficult to evaluate. These models are built with many of the same tools and under similar paradigms to conventional autoregressive next-token prediction models, e.g. large language models. The safety of embodied digital agents compared to conventional AI hinges on the importance and relevance of differentiators–in particular, how much the approach steers the space of solutions to the problem of intelligent behavior toward the set of safe solutions. Some of these differentiators could include that:
Brain data poses a stronger set of constraints than behavior only (see Section 6 for an alternative take on this idea).
Embodiment and agency pose a stronger set of constraints than lack of embodiment [156].
Optionally, connectomes and the genomic bottleneck [75] pose a stronger set of constraints and inductive biases than current AI architectures.
Optionally, causal models could have a larger range of stability and out-of-distribution validity compared to conventional models.
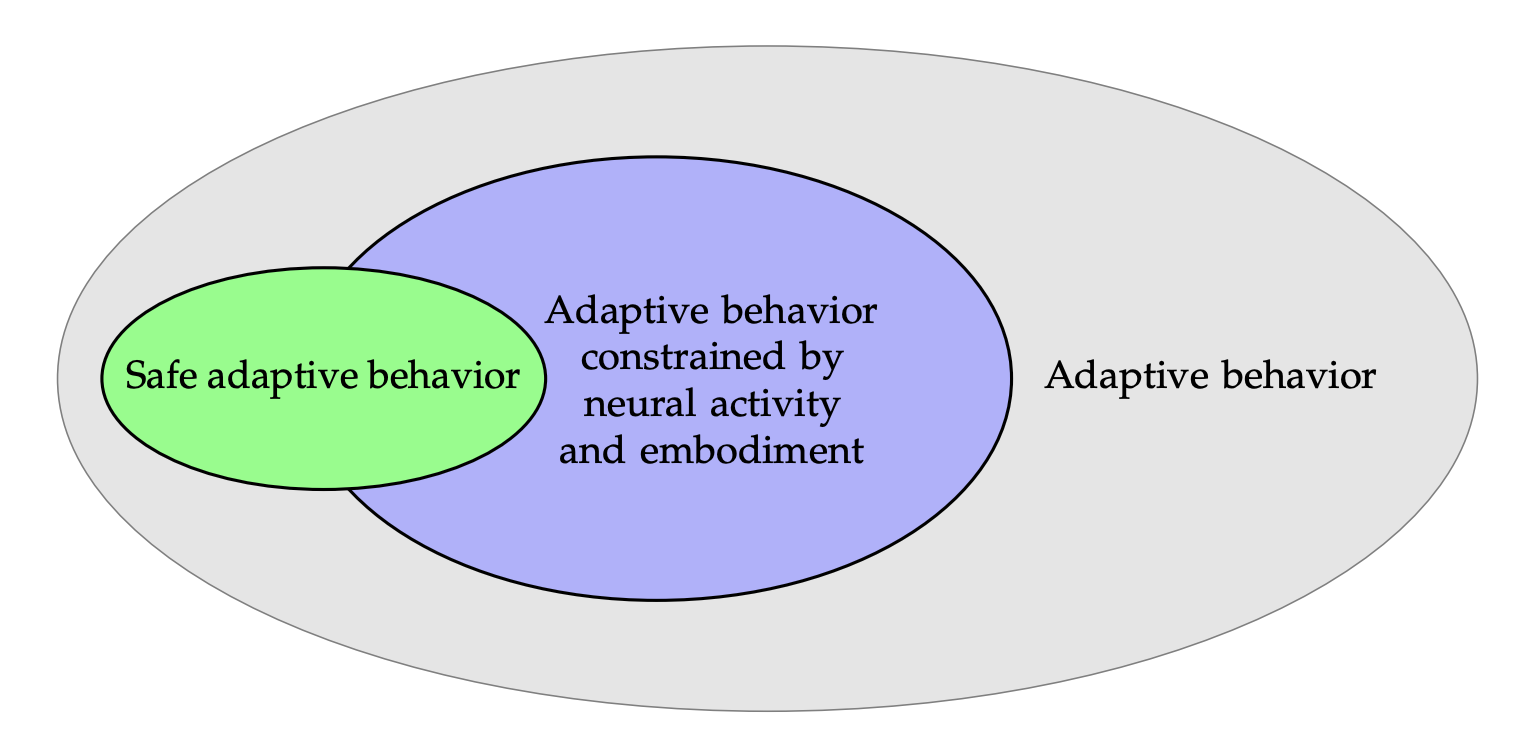
These ideas are illustrated diagrammatically in Figure 13. Out of all potential systems that have adaptive, intelligent behaviors, only a small proportion display human-compatible, safe behavior. Constraints from neural activity, embodiment, connectomics and causality may shrink the solution space toward safe behavior. Whether this premise is correct will need careful examination.
Building on the concept of constraints shaping safe behavior, Sarma et al. (2019) [229] propose a research program focused on developing biophysically detailed simulations of simple organisms, such as C. elegans, Drosophila, and zebrafish. These simulations would incorporate biomechanics within a simulated environment, providing a bottom-up approach for studying the emergence of intelligence and values in embodied agents. This aligns with the idea that embodiment and agency impose stronger constraints on behavior compared to disembodied systems. By studying the interplay of biological constraints, environmental interactions, and emergent behaviors in these simulations, researchers can gain insights into the factors influencing safe and human-compatible behavior in AI systems.
At a meta-level, embodied digital twins and virtual animals could prove useful in accelerating neuroscience, by making it easier to perform virtual experiments that can generate hypotheses. Thus, even with a narrow path toward direct impact on AI safety, accelerating the creation of large-scale datasets under rich, high-entropy, naturalistic scenarios and of virtual animals could have a large, positive effect on fundamental neuroscience research. Beyond the first-order effect of advancing neuroscience and applications in health, embodied digital twins could accelerate the virtuous cycle of influence between neuroscience and AI at the heart of NeuroAI, with positive downstream effects for AI safety.
Opportunities
Build new tools to facilitate recording ethologically relevant, high-entropy, naturalistic neural activity, and behavior in free-moving conditions, including multi-animal interactions.
Wireless neural recording devices capable of recording large numbers of neurons simultaneously in freely behaving animals.
Off-the-shelf multi-camera videography and tracking tools with high accuracy and low latency to capture movements and postures in 3D at high resolution, including in groups of interacting animals.
Fully controlled experimental environments that can be recreated in simulation, facilitating comparisons between free behavior in real and virtual animals.
Generate, aggregate, and disseminate large-scale, high-entropy datasets of naturalistic behavior.
Build and disseminate multimodal foundation models for neuroscience.
Build a zoo of standardized, adaptable virtual animals complete with bodies actuated with muscles and embedded sensors that may interface explicitly with the nervous system in simulations.
Leverage comparative neuroanatomy and evolutionary psychology to identify the simplest organisms (mammalian or otherwise) for which embodied digital twins provide the greatest insight into building human-aligned AI.
Build an ecosystem of competitions and challenges for embodied animal simulations, including multiple environments, tasks, and interactions, evaluating both short-range and long-range predictions.