NeuroAI for AI Safety
As AI systems become increasingly powerful, the need for safe AI has become more pressing. Humans are an attractive model for AI safety: as the only known agents capable of general intelligence, they perform robustly even under conditions that deviate significantly from prior experiences, explore the world safely, understand pragmatics, and can cooperate to meet their intrinsic goals. Intelligence, when coupled with cooperation and safety mechanisms, can drive sustained progress and well-being. These properties are a function of the architecture of the brain and the learning algorithms it implements. Neuroscience may thus hold important keys to technical AI safety that are currently underexplored and underutilized. In this roadmap, we highlight and critically evaluate several paths toward AI safety inspired by neuroscience: emulating the brain’s representations, information processing, and architecture; building robust sensory and motor systems from imitating brain data and bodies; fine-tuning AI systems on brain data; advancing interpretability using neuroscience methods; and scaling up cognitively-inspired architectures. We make several concrete recommendations for how neuroscience can positively impact AI safety.
Develop better cognitive architectures
This section contributed by Eli Bingham, Julian Jara-Ettinger, Emily Mackevicius, Marcelo Mattar, Karen Schroeder and Zenna Tavares.
Core Idea
The dominant paradigm in AI development focuses on rapidly testing and iterating over current models, promoting the ones with the best benchmark results. This has resulted in striking advances in AI capabilities at the expense of robust theoretical foundations. The gap between our ability to build powerful AI systems and predict their capabilities and failure modes is only growing.
A promising alternative approach, rooted in cognitive science and psychology research, is to develop cognitive architectures [64]–formal theories that specify how intelligent systems process information and make decisions. These architectures emerged as scientific efforts to understand how the human mind works, and aim to capture the core mechanisms through which an intelligent agent represents knowledge about its environment, updates it based on observations, reasons about it, and acts on the world. Because computational implementations of cognitive architectures are built using distinct modules with clear interfaces between them, we can inspect and verify each component independently–a critical feature for AI safety.
To date, most cognitive architectures aim to explain only a small set of psychological phenomena in the context of narrow task specifications, and have been painstakingly hand-engineered by human experts over many years. However, advances in cognitive science, neuroscience, and AI suggest a path toward new kinds of cognitive architecture that exhibit human-like behavior and latent cognitive structure in a far broader and more naturalistic set of tasks [296, 297]. At a high level, our approach is to build three inter-related foundation models–for behavior, cognition, and inference–along with curating the data to train them, and building a programming language around them. In this roadmap section, we argue that building such a system is within reach of today’s technology and sketch what a concerted engineering effort would entail.
Why does it matter for AI safety and why is neuroscience relevant?
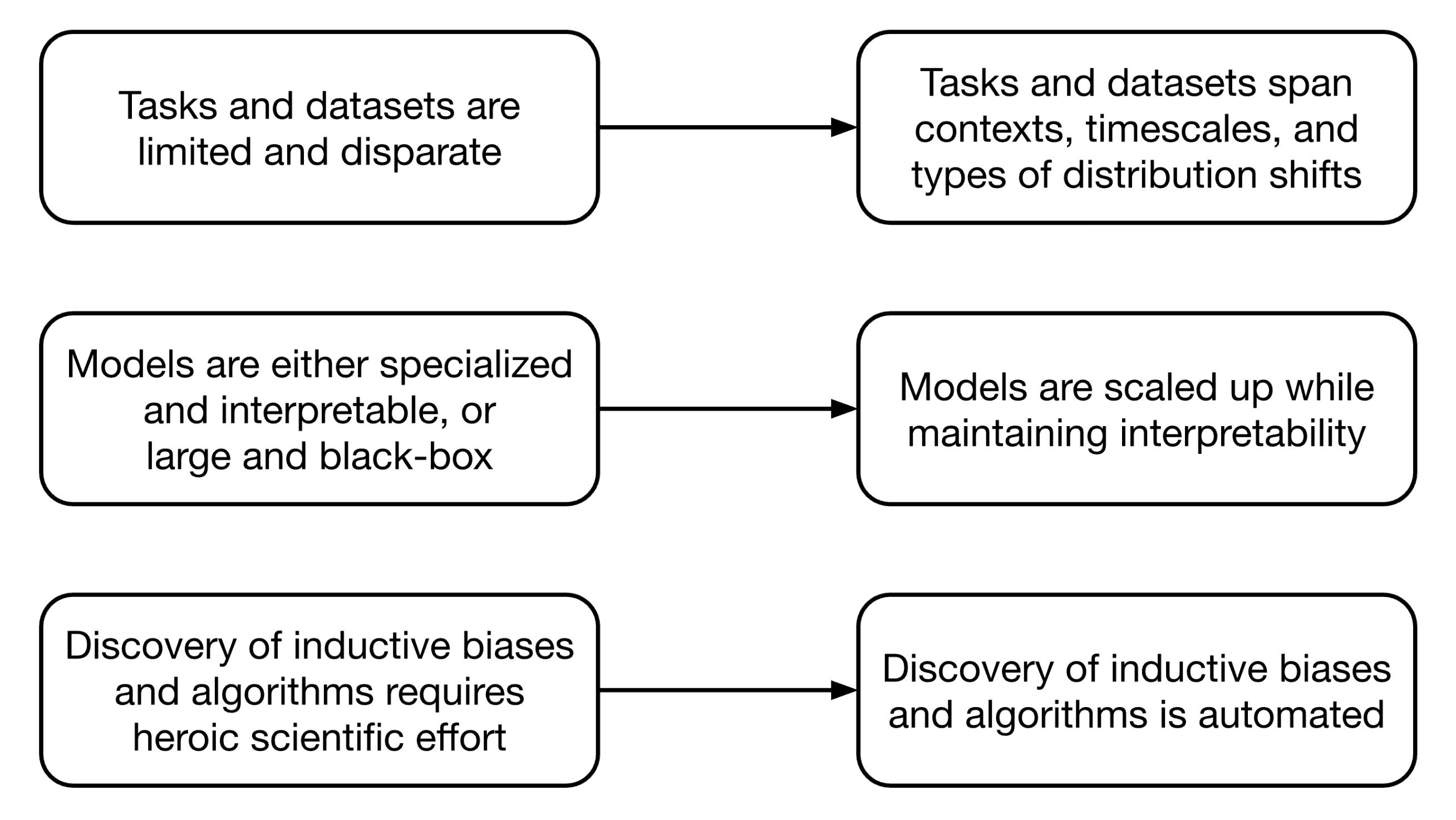
A fundamental challenge in building safe AI systems is defining what we mean by "safe" in formal, executable terms. Without such specifications, we cannot reliably engineer systems to be robust, aligned, or verifiable. A cognitive architecture that includes human-like inductive biases–innate pieces of knowledge that facilitate learning the rules of the physical and social world, like those enumerated in the foundational paper [64]–would go a long way toward addressing this challenge. These inductive biases help ensure safe behavior in several ways: they constrain learning to favor reasonable interpretations of limited data, they guide exploration of new situations, and they provide defaults for handling uncertainty. For example, humans’ innate understanding of object permanence and physical constraints helps them explore their environment safely, while basic social biases help them learn appropriate behavior from minimal examples. In addition, possessing a formal description of model inductive biases would allow researchers to predict and mitigate undesired model behavior.
However, coming up with an explicit formal specification of any of those biases outside relatively small proof-of-concept systems has proven frustratingly difficult. Our proposal aims to get around this difficulty by using experimental tasks and human behavioral data in those tasks to specify inductive biases implicitly, so that machine learning systems trained on the data will acquire the inductive bias in a scalable and predictable way. Once successfully built, a cognitive architecture offers a unified rather than piecemeal approach to specification, robustness and assurance in AI safety. We summarize how each piece of our proposal accelerates progress toward a complete cognitive architecture in Figure 16 and address these aspects of safety in the other sections below.
Details
A growing body of experimental and theoretical evidence from across AI, cognitive psychology, and neuroscience is converging on a unifying view of intelligence through the lens of resource rationality. In this paradigm, intelligent systems are analyzed at Marr’s computational level [53] in terms of the problems they aim to solve and the optimal solutions to those problems, subject to the algorithmic-level constraint that they make optimal use of their limited computational resources to do so. More extensive discussions of the history and evidence for this paradigm appear in foundational review articles [64, 298, 299] and their associated open commentaries. A wider web of connections to other fields is explored in [300, 301].
Here, we focus on the challenge of consolidating this loose consensus into a comprehensive model of the mind as a whole [302], one applicable to both the design of AI systems that are qualitatively safer and more capable than those available today, and to the analysis of real-world intelligent systems in truly naturalistic environments and behaviors (Figure 16). For each of the three aspects of AI safety considered in this roadmap, we identify key bottlenecks to consolidation for that aspect and new opportunities to overcome them afforded by recent advances in AI.
Scaling specification: benchmark tasks and experimental datasets
AI systems today are remarkably capable in many ways and frustratingly incapable in others. They have surpassed human-level performance at chess and Go, but struggle with simple physical reasoning puzzles that children can easily solve. Evidence from cognitive science suggests that the flexibility, robustness and data-efficiency that are still distinctive advantages of human intelligence are derived in part from a small number of inductive biases [64, 303]. Researchers have leveraged these insights to design benchmark tasks–tasks that can be performed by both humans and AI systems–where humans still dramatically outperform mainstream AI systems [304]. They have also built prototype AI systems for some of these tasks that leverage human-like inductive biases to match human performance [77, 296, 305].
Unfortunately, it has proven challenging to scale up from these isolated proofs of concept to formal and explicit specifications of a full suite of human-like inductive biases that can be incorporated into large-scale generalist AI systems. An alternative approach to identifying inductive biases is to replace the non-scalable step of applying human ingenuity by an inherently scalable process of curating an ensemble of experimental tasks and collecting human behavioral datasets drawn from those tasks. The tasks and data can be seen as an implicit specification of the inductive biases, in the sense that a standard machine learning model could learn the inductive biases simply by fitting the human data.
Benchmark tasks
Benchmarks are carefully designed experimental paradigms that serve as implicit specifications of desired cognitive capabilities. We propose that good benchmark tasks should respect the following desiderata:
A large gap between human and AI task performance. This gap is currently a good indicator of an area in which inductive biases could be reverse-engineered to great effect. For example, the ARC and ConceptARC benchmarks [306, 307], which were designed to test abstraction and reasoning abilities, remain unsolved to human-level performance by LLMs, despite the application of biologically implausible compute budgets. Additional examples include few-shot learning tasks like Bongard problems (learning visual concepts from a single set of positive and negative examples) [308], and physical reasoning problems like PHYRE (intuitive physics understanding) [309].
Evaluate broadly-applicable inductive biases and human-like generalization. Tasks should not be narrowly scoped, as is sometimes desirable in hypothesis-driven neuroscience experiments, but rather offer the opportunity for generalization by design. One example is Physion [310], a physical reasoning benchmark that tests the ability to predict how physical scenarios will evolve over time. This environment could be used to set up an arbitrarily broad range of scenarios across different types of objects.
Performable by humans and AI systems using the same interface. Clever design of the task interface greatly simplifies comparison of human and AI abilities. For example, ARC abstracts away visual perception by representing task puzzles as grids of integers. These grids can be visualized by human subjects by mapping each integer to a unique color, thereby creating a human-friendly interface without changing any semantics of the task. Video games are similar, in that a rendering of a chess board is a human-friendly interface to a task that can be provided to an AI system as simply a matrix of values.
Some categories of behavioral ’benchmarks’ that are aligned with our desiderata include:
Purpose-built psychology tasks. Experimental paradigms from cognitive psychology isolate specific mental processes, making them both valuable probes of human intelligence and tractable for AI systems. Their simplicity reveals the inductive biases that give humans their efficiency advantage. Tasks studying causal learning are particularly valuable as they reveal inductive biases that enable humans to learn efficiently from limited data, e.g. a tendency to interpret explanations as communicating causal structure [311].
Animal behavior. Animal behavior studies offer valuable insights into core cognitive capabilities without human-specific overlays like language or culture. Rodents demonstrate pure spatial reasoning, birds show probabilistic inference in foraging, and primates reveal exploration-exploitation tradeoffs. Recent advances in computer vision and neural recording have produced high-quality open datasets of animal cognition [205, 312, 313, 314, 315, 316, 317]. Studying cognition across species helps identify generalizable computational principles underlying behavior while avoiding overfitting to human-specific traits.
Video games. Video games offer intuitive, scalable benchmarks that both humans and AI can interact with identically [318]. While AI systems like Agent57 now master individual Atari games [319, 320], they differ markedly from human strategies. Custom game environments can probe specific cognitive capabilities where human inductive biases confer advantages, such as physical reasoning [309, 321] and causal understanding [322], where humans show distinctive advantages due to their inductive biases.
In-the-wild human behavior. Naturalistic data from strategic gameplay, forecasting, and collaborative platforms (e.g. GitHub, StackExchange) reveal human problem-solving in action [323, 324]. While analyzing this data is complex, it can illuminate cognitive processes, as demonstrated by resource-rational decision-making studies in chess [325].
Large-scale human behavioral experiments
One important limitation of existing datasets is that they typically focus on one signal–behavior or brain data–usually in one relatively constrained task. Historically, this has been due to an inherent tension between the need for rich expressive tasks, and practical limits imposed by recording technology (e.g., EEG, fMRI). Observing a broad distribution of behaviors is important to get a broadly generalizable picture of brain representations [326, 327, 328, 329, 330, 331, 332, 333, 334]. Access to a variety of behavioral measurements and neural activity in rich semi-naturalistic tasks will provide critical complementary evidence to the more isolated datasets available through past research.
Several recent approaches demonstrate the power of large and expressive datasets in informing machine models of human cognition. A recent study trained machine learning models on a large corpus of human data that specifically related to making risky decisions [335]. Another recent work assembled data from 160 psychology tasks as fine-tuning data for a LLM [336]. These approaches produced models that could predict and simulate human behavior in a broad set of psychology tasks. Still, existing datasets are insufficient.
We need to systematically study how humans handle distribution shifts. Some of the most impressive real-world examples of human cognition consist of one-shot learning and decisions in a changing world, without the possibility for an extended trial-and-error learning period. However, many psychology tasks involve repeated experience with stationary task statistics. To study human cognition under distribution shifts will involve carefully designed experiments that introduce controlled changes to task contexts and measure how people respond, as well as fine-grained behavioral measurements in complex real-world environments.
Recent technological advances in machine vision, simulation, and pose tracking, have made it possible to collect high-resolution behavioral datasets at scale. This includes high-resolution behavior collected in VR, where people can freely move around in an omnidirectional treadmill, while recording eye fixation, pupil dilation (an index of attention and surprise; [337, 338]), and body pose. Advances in neural models of pose detection [339, 340] now also make it possible to build rich datasets of naturalistic behavior in other animals, such as automatic tracking of behavior in captive marmoset colonies.
Scaling assurance: programming languages for NeuroAI
Resource-rational analysis offers a powerful and unifying conceptual framework for assurance in AI safety. However, existing software doesn’t scale to rational models of sophisticated AI agents, while the standard taxonomy of decision-making tasks and associated algorithmic and analysis tools is increasingly ill-matched to the complex patterns of interaction in LLM-based AI agent systems. This could be addressed by developing programming languages that perform them mechanically, much like the growth and impact of research in deep learning was catalyzed by differentiable programming languages like PyTorch [160].
Languages of thought
Universal probabilistic programming languages, capable in theory of expressing any computable probability distribution [341], were first developed by cognitive scientists as promising candidates for a language of thought [342]. Since then, probabilistic programming has produced a number of widely used open source languages, such as Stan [343], WebPPL [344], PyMC [345], Pyro [346], NumPyro [347], Turing [348] and Gen [349], and evolved into a thriving interdisciplinary research field in its own right [350].
We do not attempt to review the many technical challenges of developing general-purpose PPLs. Instead, we focus on practical limits to expressiveness in mature existing PPLs that are believed to be especially important for modeling cognition and have been individually de-risked to some extent in smaller prototypes.
Using foundation models as primitive distributions: First, the language should make it possible in practice to represent the widest possible variety of hybrid neurosymbolic models [351] that use deep neural networks to parametrize conditional probability distributions. The logical limit of this direction is foundation models as primitive conditional distributions, particularly the key special case of foundation model conditional distributions over latent probabilistic programs [296].
Incorporating modular inductive biases: Researchers have produced copious evidence for common architectural modules of human cognition such as perception, mental simulation, pragmatic language understanding, working memory, attention, and decision-making [296, 297]. While we advocate for implicit specification via suites of tasks and large-scale behavioral datasets, a universal language for cognitive modeling should be able to incorporate explicit specifications as well, and allow them to be studied, modified, and validated independently while maintaining clear interfaces with other components. Cognitive models that invoke these modules enable transparent tracking of information flow between different cognitive processes, making it possible to understand how different components interact. This architecture creates natural points for implementing safety constraints and monitoring, as the behavior of each module can be verified independently of others [80]. The cognitive foundation models we propose can be viewed as a newer generation of cognitive architecture, leveraging massive datasets and flexible models to scale to a much wider set of more naturalistic behaviors.
Languages of action
In performing resource-rational analysis of complex behavior or designing or interrogating a resource-rational AI agent, it is often necessary to formally specify a task. This is subtly distinct from the aim of the previous section: cognitive models relate an agent’s internal beliefs and observations, while a task relates an agent’s sensors and actions to the state of the outside world. In practice, tasks are often thought of as monoliths that are either exactly the same or formally unrelated. When faced with a new task, a researcher must either force it into an existing template that allows reuse of algorithms and analysis tools while eliding important structure, or develop a new specification and implement new algorithms and analyses from scratch.
An alternative and more scalable approach is to specify tasks as executable programs. There are many theoretical results in cognitive science that reduce higher-level tasks to sequences of one or more probabilistic inference computations [189, 352, 353, 354, 355]. Despite the leverage afforded by a single computational bottleneck, these results tend to be treated as something akin to folk wisdom, often cited but rarely examined or implemented. However, we believe that other advances have already de-risked these from open-ended research questions into well-scoped engineering problems:
Identifying task programming primitives: We require a concrete set of primitive programming constructs which can combinatorially generate many tasks of interest and have known reductions to probabilistic inference. Graphical modeling notations in causal inference extend the probabilistic graphical modeling notations that later grew into PPLs [356]. These include structural causal models and counterfactuals [219], which can represent any causal inference task and have already been implemented in prototype causal PPLs [357], as well as the closely related formalism of influence diagrams [358] and their recent mechanized [359] and multi-agent [360] extensions. Influence diagrams enable generalization of classical control/RL-as-inference reductions in cognitive science [352, 361] and unify many problems in AI safety like reward hacking and value alignment [362, 363, 364, 365]. An orthogonal set of primitives are first-class reasoning operations that may be recursively nested and interleaved with model code [366, 367], allowing compositional specification of inverse reasoning and meta-reasoning tasks like inverse reinforcement learning in terms of their forward or object-level counterparts [368, 369].
Encoding optimization, logic and resource usage: A complete language for resource-rational cognitive modeling should also go beyond probability to allow interleaving similar first-class programming constructs for three other modes of declarative reasoning, namely optimization, logic, and the use of limited computational or other resources. These four modes are essential for performing rational analysis and are closely related mathematically [370].
Specifying inference algorithms: We advocate for algorithms that asymptotically match exact inference with large compute, and whose specifications are primarily learned rather than handwritten. Research in computational cognitive science has led to many individual algorithms that partially satisfy one or both of these, from the original wake-sleep algorithm [371] to amortized variational inference [372] to modern gradient-based meta-learning [298]. In the next section, we argue for a maximalist interpretation of these goals over the use of existing algorithms.
Scaling robustness: foundation models of cognition
Cognitive scientists have identified properties of human intelligence that make it robust in the face of unanticipated tasks and environmental shifts. Chief among these is the ability to manipulate representations of existing knowledge, to compose them into new knowledge and skills. These representations are understood formally as hybrid neural-symbolic programs [351] in a probabilistic "language of thought" [296, 373], and the synthesis and evaluation of these programs is formalized as Bayesian or probabilistic inference problems, whose solutions make adaptive and optimal use of people’s limited computational resources [299]. These discoveries are ripe for consolidation into a unified computational toolkit for assessing the robustness of existing AI systems and designing new ones that exhibit human-like robustness by construction.
We propose to transform this approach through the development of foundation models of cognition that can automatically synthesize and scale up the specification of models and algorithms. We propose an approach that builds on the theoretical insights of resource rationality to maintain interpretability as a core design principle. We argue for a layered approach whereby each model layer extracts a different type of information from the massive training data. In particular, we propose the development of behavioral foundation models to predict and simulate behavior in different task domains; cognitive foundation models to capture the representations and symbolic structures underlying behavior; and inference foundation models to specify the inference algorithms in settings of limited resource availability (Figure 17). Notably, all three models can be trained on the same large-scale data described previously, but each will have different inputs and outputs, resulting in different functions being learned.
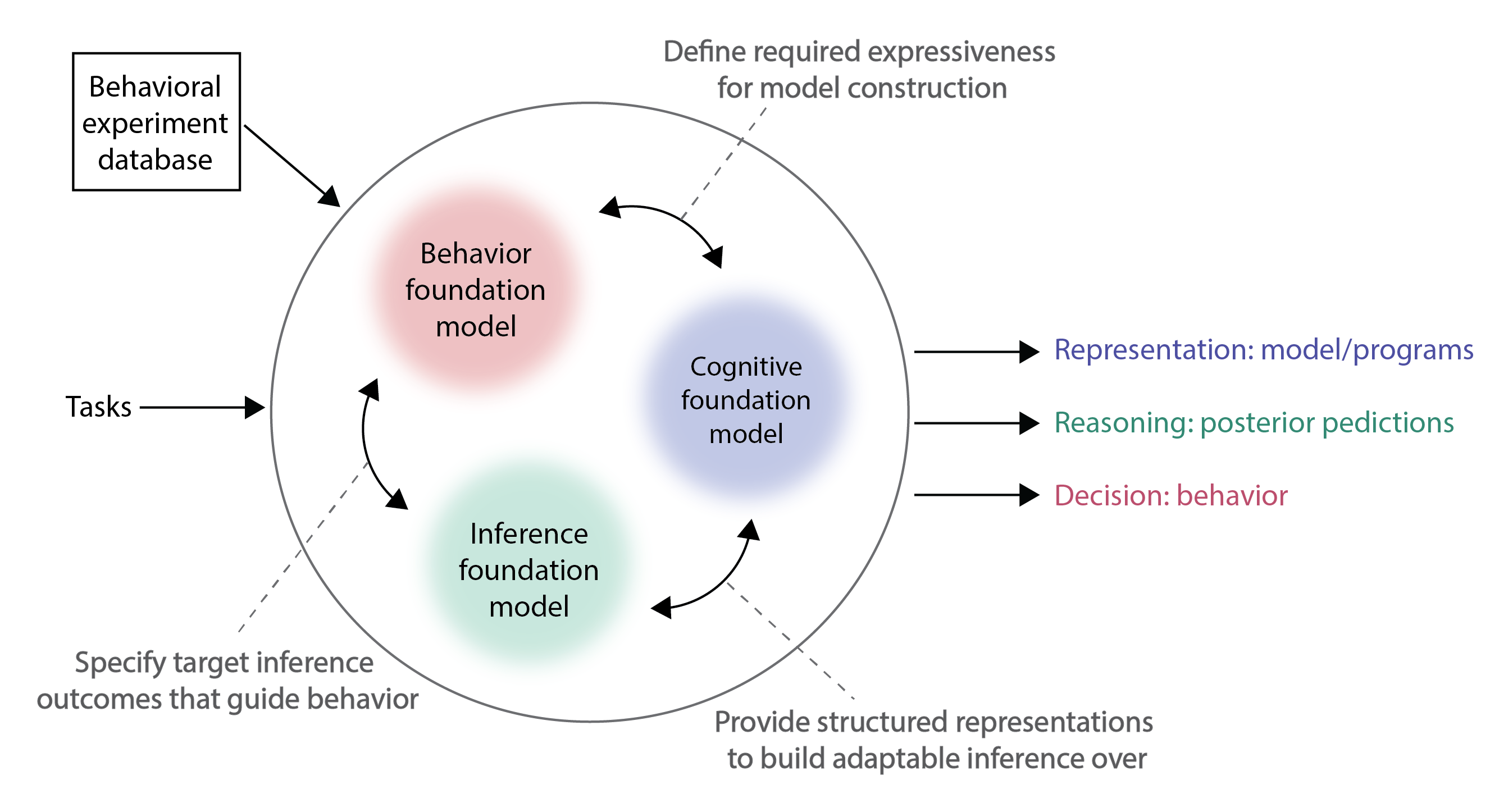
Behavioral foundation models
Behavioral foundation models leverage massive experimental datasets of human or AI behavior to predict responses across a diverse set of tasks and contexts simultaneously. As a result, these models can identify common patterns and principles shared across tasks, enabling both better prediction of behavior in novel situations and the discovery of previously unnoticed regularities and biases. Additionally, the behaviors of biological organisms simulated by such models can be directly contrasted with those of normative agents and non-cognitive AI systems, surfacing differences in their responses to unexpected input. We briefly consider data modalities and associated pretraining tasks for a behavior foundation model, closely aligned with the previous section on data collection.
Modality: human behavior The primary goal of a behavioral foundation model is to accurately predict the responses of a biological or AI agent across different domains, including simulating behavior in naturalistic tasks and domains outside the training set. Foundation models specified at the group level can be fine-tuned to a specific individual, capturing behavioral idiosyncrasies to enable maximally accurate predictions at the individual level.
Modality: non-human animal behavior Our discussion has focused on advancing AI safety by modeling human cognition and endowing AI systems with human-like capabilities. Pretraining a behavior foundation model on non-human animal behavioral data might be helpful for this goal in a few ways. For example, a foundation model can simulate behavior of a wide variety of animal species might be better at extrapolating to new types of non-cognitive AI systems, especially embodied AI systems like robots whose safety properties may be harder to anticipate and collect data on (see also Section 3 for related ideas).
Cognitive foundation models
While a foundation model of behavior may capture behavior across multiple domains, it does not serve as an explanatory framework for the innate cognitive and biological constraints that shape intelligence, the learning algorithms available across development, and the kinds of behavioral pressures and experiences that drive learning. An expressive and interpretable foundation model of cognition requires going beyond matching behavior in psychology tasks, to show and explain human-like behavior in contexts that better approximate the real world, where agents have changing goals and need to construct task representations to act on the world.
Rather than treating foundation models of behavioral data as the sole end goal, we can use them to accelerate the creation of domain-specific, interpretable, quasi-mechanistic models of cognition. These models take the form of probabilistic programs that can be run forward to randomly generate behavioral data or run backward to explain it. A foundation model of behavior eliminates one human bottleneck by circumventing the need to run a new human experiment to test every new model or hypothesis, but the manual specification and adjustment of probabilistic models of cognition by human experts is still a brake on progress.
To remove this second bottleneck, we propose training a foundation model for cognitive model synthesis that learns the mapping from behavioral data and task specification to the source code of a probabilistic program. While this is agnostic to the particular language used to represent those programs during either pretraining or testing, an obvious choice is the language described in the final section. Instead, we favor an all-of-the-above approach to curating pretraining data and tasks.
Modality: Program source code The proposed foundation model could synthesize probabilistic programs given a task specification and/or behavioral data. Such a model would likely reap large benefits from extending a pretrained open LLM for code, and could in theory be trained with maximum marginal likelihood on data generated from the behavior foundation model. Other pretraining datasets that might help probabilistic program generation are curating extensive corpora of probabilistic models of cognition, as well as probabilistic programs in other non-cognitive languages and domains.
Modality: Natural language reasoning chains While we do not expect this foundation model to be used to generate natural language, reasoning chains produced by humans are a scalable and high-content source of information about cognitive processes and would likely be a useful auxiliary pretraining task, especially since the corpus of handwritten cognitive models is relatively small.
Modality: Measurable correlates of cognition Data from human experiments might include low-level behavioral signatures of cognitive processes, such as eye-tracking or mouse movement, that could prove useful for auxiliary pretraining tasks.
Inference foundation models
The probabilistic programs synthesized by the cognitive foundation model can be used in conjunction with Bayesian inference to explain behavioral data in terms of the programs’ interpretable latent structure, or to generate behavior that exhibits human-like flexibility. However, since Bayesian inference is intractable in general, to generate resource-rational behavior, it is ultimately necessary to specify an approximation that is resource-rational, a challenging and labor-intensive endeavor that typically requires human expertise and remains a primary barrier to the wider use of Bayesian methods in NeuroAI.
To accelerate progress, we propose to learn an inference foundation model, which would directly map arbitrary resources, priors and data to resource-rational posterior predictions. We briefly consider possible output modalities and associated pretraining tasks that would leverage the previous two foundation models of behavior and cognition, as well as complementary human experimental data.
Modality: Posterior predictive inferences. Inference foundation models would serve as computational primitives in cognitive architectures, providing efficient approximate inference over a broad range of reasoning tasks. Training would require assembling diverse datasets of models, data, and ground truth posterior inferences. These can be constructed by mining the scientific literature for published models and inference results, generating synthetic data from cognitive foundation models, running exact inference or gold-standard methods like Hamiltonian Monte Carlo [374], and collecting human behavioral data from experiments carefully designed to elicit subjects’ prior and posterior beliefs as observable outcomes.
Modality: Experimental correlates of resource expenditure. Beyond models and inference results, a potentially useful auxiliary pretraining task is predicting measurable proxies of computational and cognitive resources expended during inference. For automated methods, we can directly track computational operations, energy usage, and economic costs. For humans, we can measure behavioral proxies like response times in decision-making tasks, eye movements in visual inference, or move times in strategic games like chess. These resource measurements enable training inference models that make human-like rational tradeoffs between accuracy and computational cost.
Evaluation
Building foundation models of cognition from human data presents promising opportunities for AI safety but faces several significant technical challenges:
Collecting behavioral and especially neural data of sufficient scale and quality to train foundation models is expensive and time-consuming.
Training new kinds of foundation models requires substantial computational resources.
Developing PPLs is engineering-intensive and technically complex, on par with developing differentiable programming languages like PyTorch.
Fortunately, the technical risks are mostly independent of one another and have standard mitigations. The potential payoff is significant: formal, executable specifications of human-like intelligence that could fundamentally change how we develop AI systems. Rather than treating safety and robustness as properties to be added after the fact, these specifications could allow us to build systems that inherit human-like inductive biases from the ground up. These could include graceful degradation under uncertainty, appropriate caution in novel situations, and stable objectives despite distribution shifts–precisely the properties needed for safe and reliable AI systems.
Opportunities
Design large-scale tasks and human experiments that implicitly specify human-like inductive biases
Create or curate a comprehensive suite of ARC-like benchmark tasks where humans greatly outperform conventional AI systems thanks to superior inductive biases
Collect large datasets of behavior, cognitive function and neural activity from humans engaged in these benchmark tasks who are tracked over many tasks and subjected to many domain shifts
Develop a probabilistic programming language for engineering and reverse-engineering safe AI
Support inference in probabilistic programs that invoke multimodal LLMs as primitive probability distributions, including LLMs that synthesize probabilistic programs in the same language
Augment the base probabilistic programming language with a standard library of inductive biases drawn from across cognitive science and neuroscience
Enable the creation of formal, fully executable specifications of arbitrary cognitive tasks by borrowing extra syntax from causal inference and giving it a meaning through systematic reduction to probabilistic inference
Build a foundation model of cognition
Train a behavioral foundation model that can accurately simulate human and non-human animal behavior across many different experimental tasks, subjects and domain shifts
Train a cognitive foundation model for mapping task specifications to human-interpretable programs in a probabilistic "language of thought" that can be used to generate or explain behavior within a specific context
Train an inference foundation model for mapping programs generated by the cognitive foundation model and data to adaptive behavioral outputs